Every time there is a new provisioning request, we have a logic in place to look at the container units on each of the hosts and pick the host with the least container units.
We have defined flavors - small(CPU:1 , RAM: 4GB), medium(CPU:2 , RAM: 8GB) and large(CPU:4 , RAM: 16GB). The container units are 1 unit for small, 2 units for medium and 4 units for large in accordance to the ratio of resources allocated to them.
This is a very primal balancing algorithm we have in place but it doesn’t look at the resource utilization. As a result we have a host where all the containers are heavily used and the load becomes too much on it causing us to restart the LXD node to get rid of any zombie processes or the likes of it.
The true solution to this is to have some form a dynamic rebalancing of containers across hosts based on the resource usage. But LXD doesn’t provide anything in this space.
What suggestions do you have to address this issue which I am sure a lot of you have faced already. I like LXD but it makes tasks like this very difficult to solve without spending a lot of time in building a solution to the common problems that usually are a result fo scale.
Scheduling is a hard problem and one that we currently prefer to have folks run externally from LXD.
LXD’s scheduler simply picks whichever active node has the fewest number of instances. That’s not meant to be perfect but it’s something
A more serious approach would need to have a scheduler be aware of:
Expected resource usage of the instance (based on its size, resource usage and application)
Performance characteristics of the host and host hardware (you’d want to track cpu, ram, storage and network separately)
Hardware performance restrictions such as NUMA domain crossing
We may at some point try to improve our default scheduler to cover some of that, though so far we’re mostly thinking of those things when discussing instance placement at a higher level and larger scale than a LXD cluster. At a level where we have inventory information as well as a better view of the entire workload being deployed, making it easier to take a placement decision.
Building such a scheduler and implementing seamless migration from one host to another would be the dream. But is there any 3rd party scheduler or some other stop gap solution that we can integrate with LXD to have a better go at scheduling?
Kubernetes im fairly certian does something like this and there is a “shim” (or something I dont know, never used it) to make it use LXD as a backend,
cough please expose container / load CPU load info the API, It would be the only reliable way I can see it working, E.G cant reach some containers over the network, but can reach LXD cough
Your missing the point, as Miker said, its modular, so rather than use docker or CRIO as the container runtime, this shim will allow it to deploy and control LXD containers.
To me there is little difference between system containers & application containers in the context of scaling, LXE exists, which Kubernetes is designed to use, which leads me to believe, it doesn’t matter to Kubernetes which underlying platform it uses (although this is experimental).
It is hard because every container is different. I have some that are databases, take a lot of horsepower, memory etc. So I may only have one or two on a server, and I have some servers with hundreds of containers. Also have redundancy issues, I have to enough spare capacity to move containers to in case I need to do maintenance on a server. Not a perfect system, but since my productions servers are pretty similar to each other, I use #of Tasks, ram used, and disks space used to balance it out
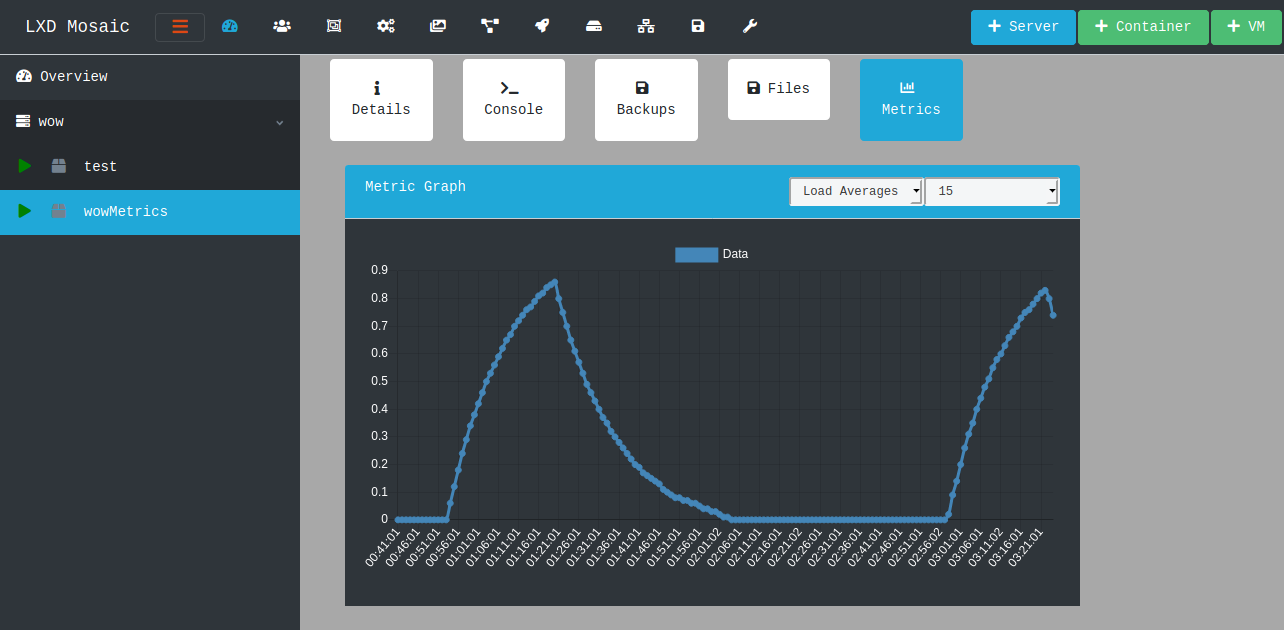
If your looking for away to extract CPU load I just managed to find a way;
Enable lxcfs loadavgs using sudo snap set lxd lxcfs.loadavg=true (requires reboot)
Obviously at this point you can just write a python script to push the values to a remote server
Or you can “abuse” LXD (say if your containers dont have network but a central server can reach the LXD instance) and instead write a crob job / script to cat /proc/loadavg using cloud-config you can then use the Files API to pull the loadavgs out of the file you created (then use the files api to delete the file once you have read it)
I managed to automate the process into my program tonight, this has also been a long running pain for me, so here’s a celebratory graph.
BTW installed it on my servers. I love it. Going to try on second cluster in two days, and then see if I can move container between them… ha ha. Give a guy an inch and now I want to break it.
Yes, I will be happy to work with you on it. I’m going to start working on it on my two testing clusters and then my new working cluster(probably next month, waiting on 3.21 patches) to see if there are any problems before implementing it on production cluster. And I will have a long list…
It did not find it really I had Q9 and Q0. since I put Q0 as first cluster member it found that one and then list Q9 but with Q0 name. I then went to Alias and made it Q9 and it refresh find. I think it need some refresh button. I am going to create a another cluster tomorrow and see how it deals with another cluster.