Oh and in your case since it’s crashing during a filesystem write, can you check that your filesystem isn’t full or out of inodes?
@stgraber disk isn’t full (37% capacity) or out of inodes (at 8% capacity). Reverting to 3.16 has a similar issue. The database is fairly huge but I’m compressing it now.
snap refresh lxd --channel=3.16/stable suffers a similar issue, the snap command is hung, lxd process continually restarting.
Actually thinking about it, I tried to be clever and run lxd in gdb, so the above trace might be a red herring. Here’s what it’s currently dumping to syslog:
Sep 9 16:24:34 lxd-host-303 systemd[1]: snap.lxd.daemon.service: Main process exited, code=exited, status=1/FAILURE
Sep 9 16:24:34 lxd-host-303 systemd[1]: snap.lxd.daemon.service: Failed with result 'exit-code'.
Sep 9 16:24:34 lxd-host-303 systemd[1]: snap.lxd.daemon.service: Service hold-off time over, scheduling restart.
Sep 9 16:24:34 lxd-host-303 systemd[1]: snap.lxd.daemon.service: Scheduled restart job, restart counter is at 127.
Sep 9 16:24:34 lxd-host-303 systemd[1]: Stopped Service for snap application lxd.daemon.
Sep 9 16:24:34 lxd-host-303 systemd[1]: Started Service for snap application lxd.daemon.
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: => Preparing the system
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Loading snap configuration
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Setting up mntns symlink (mnt:[4026532656])
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Setting up kmod wrapper
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Preparing /boot
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Preparing a clean copy of /run
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Preparing a clean copy of /etc
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Setting up ceph configuration
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Setting up LVM configuration
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Rotating logs
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Setting up ZFS (0.7)
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Escaping the systemd cgroups
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ====> Detected cgroup V1
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Escaping the systemd process resource limits
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: ==> Disabling shiftfs on this kernel (auto)
Sep 9 16:24:34 lxd-host-303 kernel: [ 3768.093578] new mount options do not match the existing superblock, will be ignored
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: mount namespace: 7
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: hierarchies:
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 0: fd: 8: rdma
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 1: fd: 9: perf_event
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 2: fd: 10: memory
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 3: fd: 11: cpuset
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 4: fd: 12: freezer
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 5: fd: 13: cpu,cpuacct
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 6: fd: 14: devices
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 7: fd: 15: pids
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 8: fd: 16: blkio
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 9: fd: 17: hugetlb
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 10: fd: 18: net_cls,net_prio
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 11: fd: 19: name=systemd
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: 12: fd: 20: unified
Sep 9 16:24:34 lxd-host-303 lxd.daemon[18560]: lxcfs.c: 152: do_reload: lxcfs: reloaded
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: => Re-using existing LXCFS
Sep 9 16:24:34 lxd-host-303 lxd.daemon[33104]: => Starting LXD
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: fatal error: unexpected signal during runtime execution
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: [signal SIGSEGV: segmentation violation code=0x2 addr=0x7f8d7932d000 pc=0x7f8d80420156]
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: runtime stack:
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: runtime.throw(0x12c5914, 0x2a)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/snap/go/4301/src/runtime/panic.go:617 +0x72
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: runtime.sigpanic()
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/snap/go/4301/src/runtime/signal_unix.go:374 +0x4a9
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: goroutine 39 [syscall, locked to thread]:
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: runtime.cgocall(0x101be00, 0xc000310f00, 0x0)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/snap/go/4301/src/runtime/cgocall.go:128 +0x5b fp=0xc000310ed0 sp=0xc000310e98 pc=0x40eaeb
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/canonical/go-dqlite/internal/bindings._Cfunc_dqlite_run(0x7f8d6c000940, 0x7f8d00000000)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011_cgo_gotypes.go:354 +0x49 fp=0xc000310f00 sp=0xc000310ed0 pc=0x898bd9
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/canonical/go-dqlite/internal/bindings.(*Server).Run.func1(0x7f8d6c000940, 0x0)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/canonical/go-dqlite/internal/bindings/server.go:265 +0x56 fp=0xc000310f38 sp=0xc000310f00 pc=0x89b906
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/canonical/go-dqlite/internal/bindings.(*Server).Run(0x7f8d6c000940, 0x1319ba8, 0x0)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/canonical/go-dqlite/internal/bindings/server.go:265 +0x2f fp=0xc000310fa0 sp=0xc000310f38 pc=0x899f5f
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/canonical/go-dqlite.(*Server).run(0xc000312690)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/canonical/go-dqlite/server.go:234 +0x54 fp=0xc000310fd8 sp=0xc000310fa0 pc=0x8ae104
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: runtime.goexit()
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/snap/go/4301/src/runtime/asm_amd64.s:1337 +0x1 fp=0xc000310fe0 sp=0xc000310fd8 pc=0x468921
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: created by github.com/canonical/go-dqlite.(*Server).Start
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/canonical/go-dqlite/server.go:126 +0x54
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: goroutine 1 [select]:
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/canonical/go-dqlite.(*Server).Start(0xc000312690, 0x14dbc40, 0xc000318660, 0x1, 0x14bb9c0)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/canonical/go-dqlite/server.go:136 +0x160
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/lxc/lxd/lxd/cluster.(*Gateway).init(0xc000350000, 0xc0003169a0, 0xc0003001e0)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/cluster/gateway.go:588 +0x4a4
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: github.com/lxc/lxd/lxd/cluster.NewGateway(0xc000316020, 0xc000340070, 0xc00028b820, 0x2, 0x2, 0x0, 0x23, 0xc000241180)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/cluster/gateway.go:59 +0x1d0
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: main.(*Daemon).init(0xc0001d6b40, 0x4108c0, 0x60)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/daemon.go:615 +0x7ac
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: main.(*Daemon).Init(0xc0001d6b40, 0xc0001d6b40, 0xc0002a2240)
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: #011/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/daemon.go:496 +0x2f
Sep 9 16:24:38 lxd-host-303 lxd.daemon[33104]: main.(*cmdDaemon).Run(0xc00019cf80, 0xc000241b80, 0xc000182840, 0x0, 0x4, 0x0, 0x0)Ah so it probably didn’t get to refresh due to it being stuck in that restart loop.
You can try:
- systemctl stop snap.lxd.daemon snap.lxd.daemon.unix.socket
This may hang, if it does, in a separate terminal, locate and kill any lxd process you find.
Once that returns, lxd should be properly stopped, then try the snap refresh lxd --channel=3.16/stable, that should then let you replace the snap and have it start up as 3.16.
The above syslog output was what 3.16 was doing, it was bootlooping (spamming that same message repeatedly). I brought the instance up by fishing out a copy of the dqlite db from before it upgraded, and swapped the entire database dir out for the broken one (I’ll have to see if any containers are missing) between startup attempts.
Did you still want a copy of the db?
I basically have two types of servers here…they are all on 3.17
Basically it lloks like they can’t talk to dbserver
Or is it possible to go back to 3.16
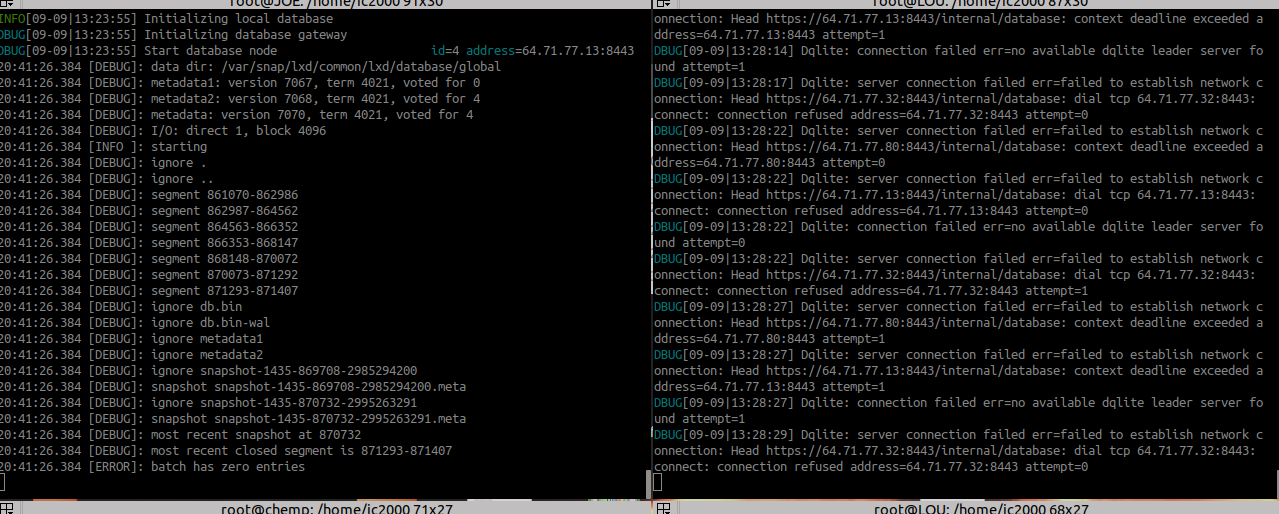
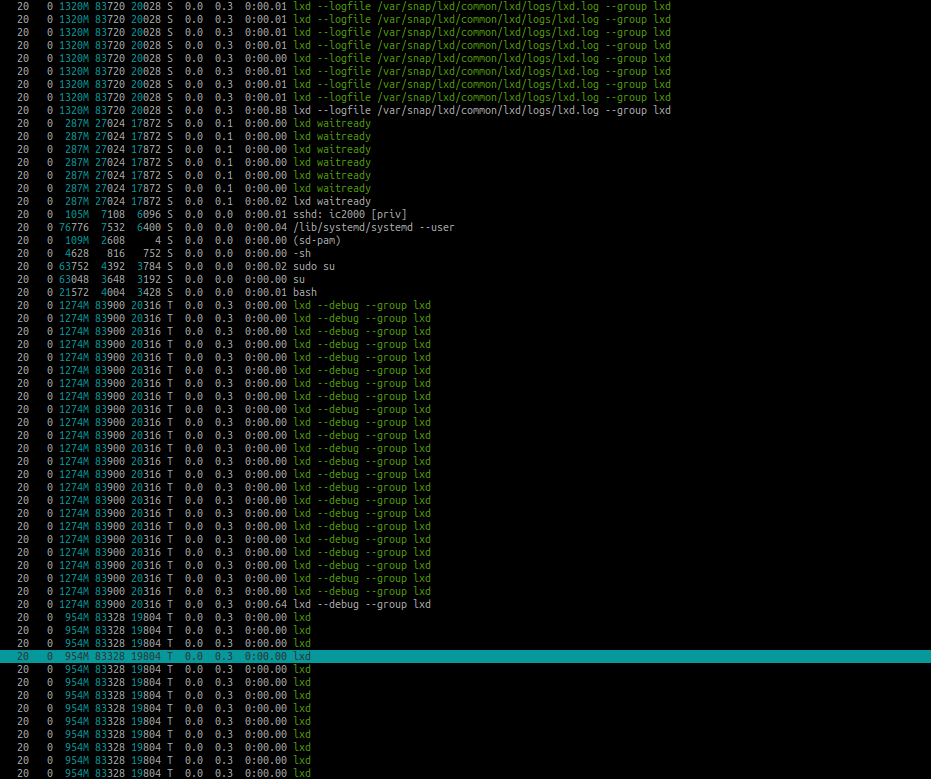
You really should have started your own topic, I believe yours is unrelated to mine and having both together causes confusion that does not help.
Please check out my two screen shots below.
Can you show ps fauxww?
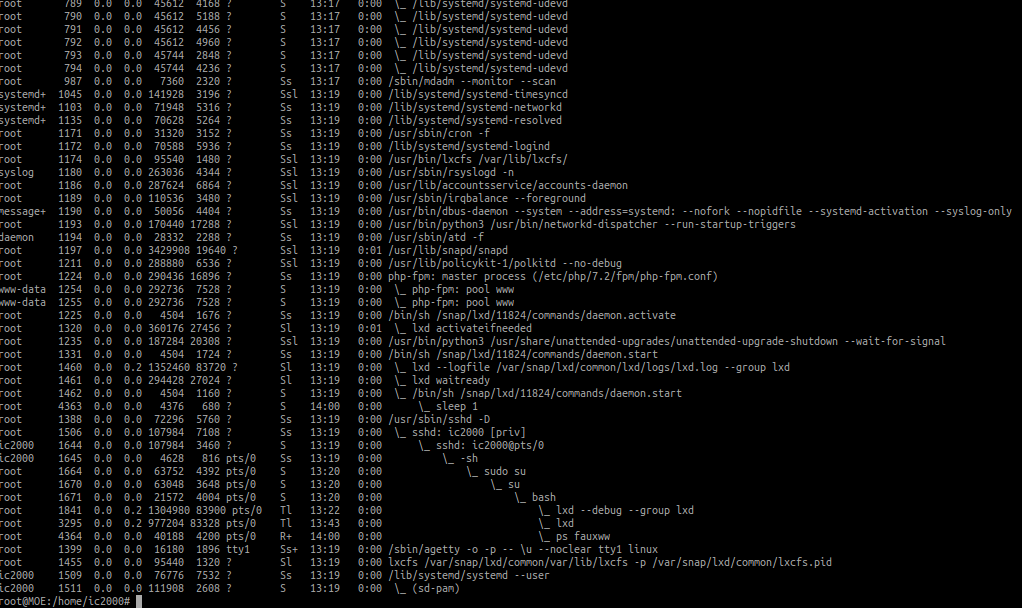
Anyway to read database in each node to see which one is in better condition?. I am afraid when one goes bad, it spreads it to all.
I’ve taken a look at this and as far as I can see it is not getting as far as doing a schema update during start. Instead it is having trouble reconnecting to the cluster when starting up.
I would appreciate @freeekanayaka taking a look at this, as it seem to be hanging here https://github.com/lxc/lxd/blob/master/lxd/daemon.go#L704-L712
in this part https://github.com/lxc/lxd/blob/master/lxd/db/db.go#L178-L214

Sorry about that, it was about 2am and I got woken up to a page, and they looked like very similar issues, and I didn’t want to overrun the team with redundant threads.
I’ll start another one now.
I understand been there myself. Hard enough to get these simple disasters fixed.
1 Like
Indeed, you have far too many LXD processes for my liking 
You should do:
- rm /var/snap/lxd/common/lxd/unix.socket
- systemctl stop snap.lxd.daemon snap.lxd.daemon.unix.socket
- Kill any leftover
lxdprocess you notice
Once that’s all done, run:
- lxd --debug --group lxd
That should give you a single clean LXD running in debug mode directly attached to your terminal.
Tried it on two servers, MOE, the bottom screen is one of the main db servers, notice it gives batch has zero errors and does not go on.
Curlyjoe is trying to find someone to talk to, so I guess he is ok.
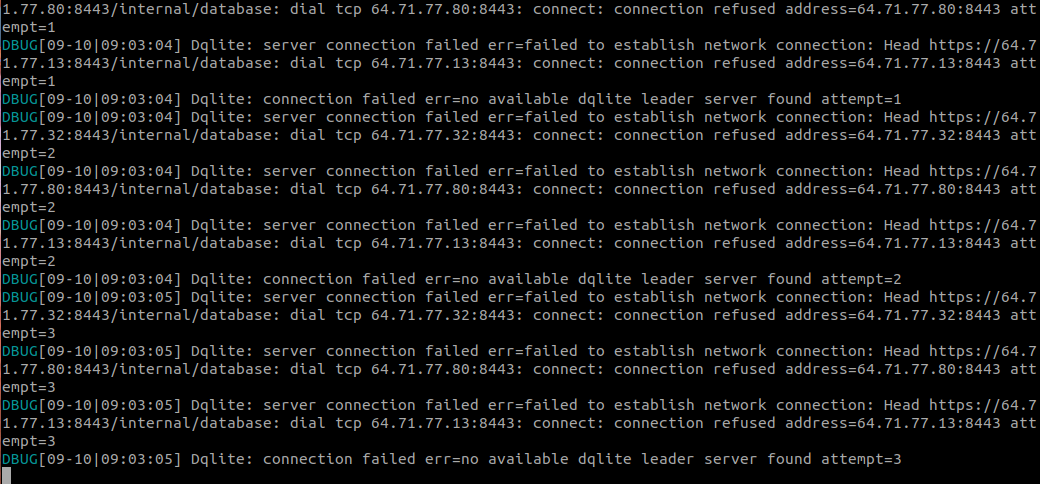
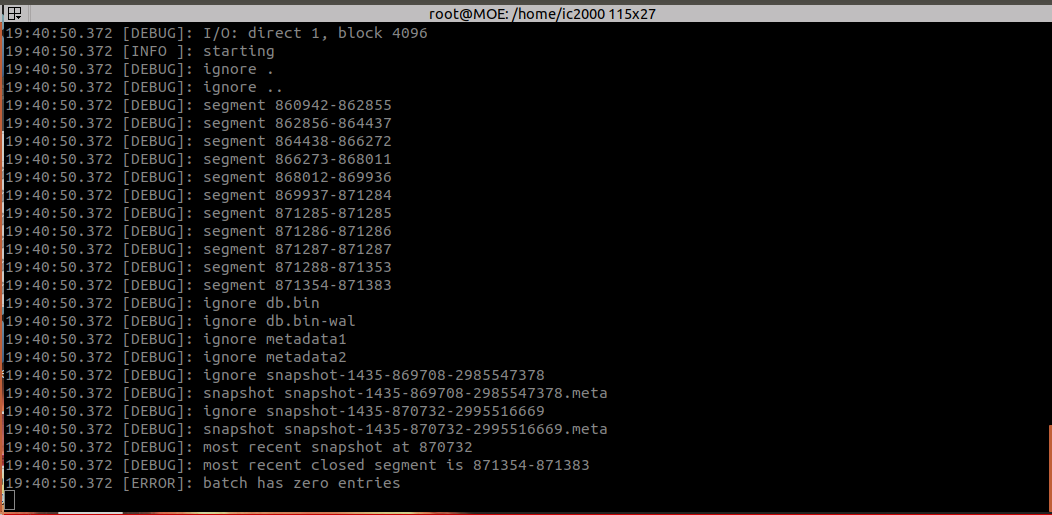
Ok, I’ve seen this once I believe, that’s definitely a DB bug that @freeekanayaka will need to look into next week (so we’ll need that DB dump so we can reproduce it). There is a very good chance that undoing the last transaction on all 3 servers will just unblock things though and as that transaction is most likely the failed upgrade, this shouldn’t cause any data loss.
Thanks Again… Looks like it is working great again