My containers are running…
Nothing else works
Afraid of rebooting
lxc cluster list
Error: Get “http://unix.socket/1.0”: dial unix /var/snap/lxd/common/lxd/unix.socket: connect: connection refused
All typical kickstarters don’t seem to work
pkill -9 -f “lxd --logfile”
systemctl restart snap.lxd.daemon
I eventually got all to say Started on snap start lxd.daemon.
But all lxc commands still go to la la land on three machines.
One of the four machines gives Error: Get “http://unix.socket/1.0”: dial unix /var/snap/lxd/common/lxd/unix.socket: connect: no such file or directory
Where do I start to get this running without breaking the running containers.
Hope this helps, looks to me like it didn’t upgrade fully and the database got stuck… But then it could something completely different.
BTW Q1 to Q4, last I remember Q1 was not a database manager. They were all running fine before upgrade and upgrade to 4.7 by themselves just fine. I had updated/reboot servers fine a couple of days before.
I can send you full file of journalctl but let me know where to send it.
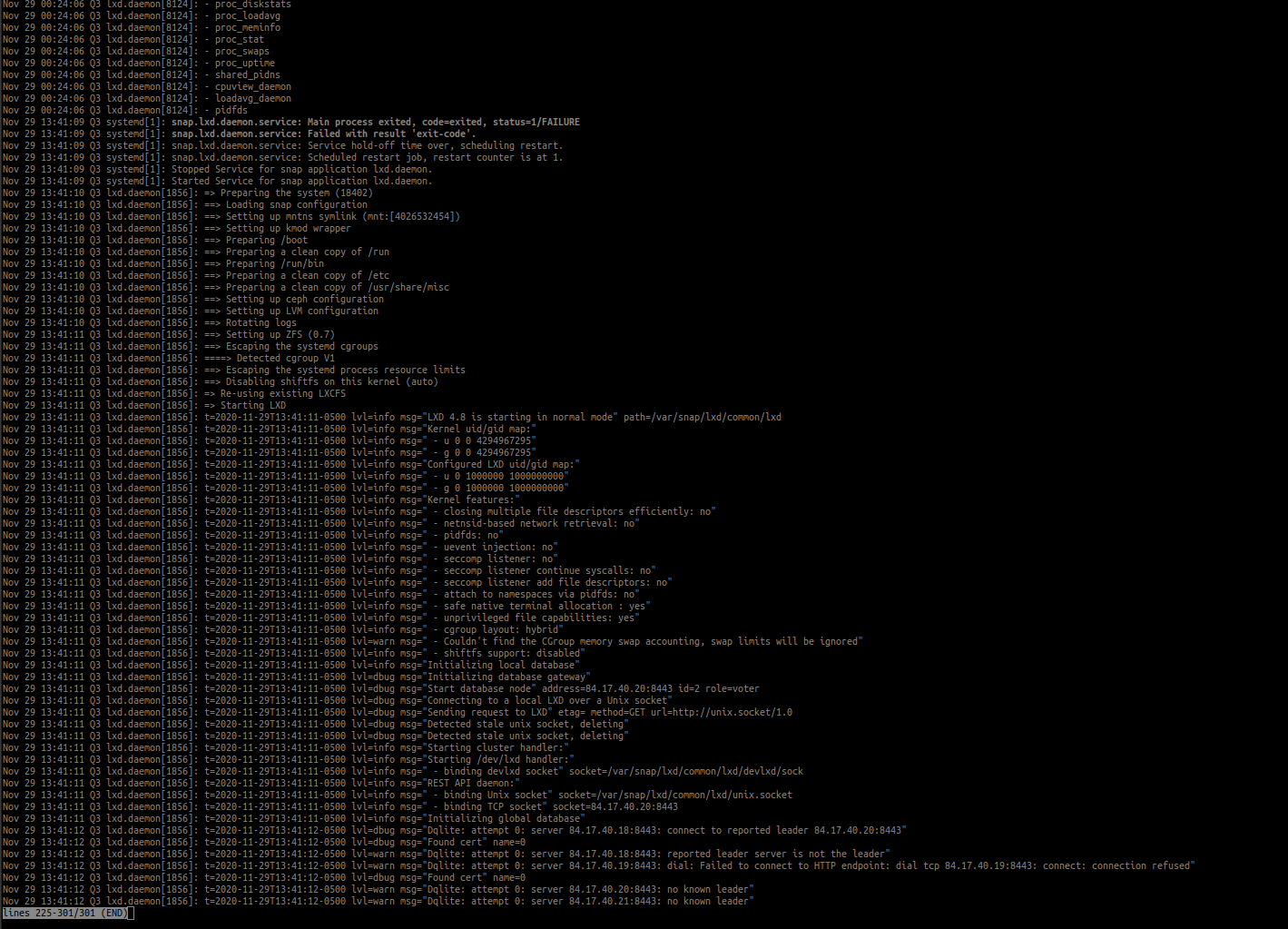
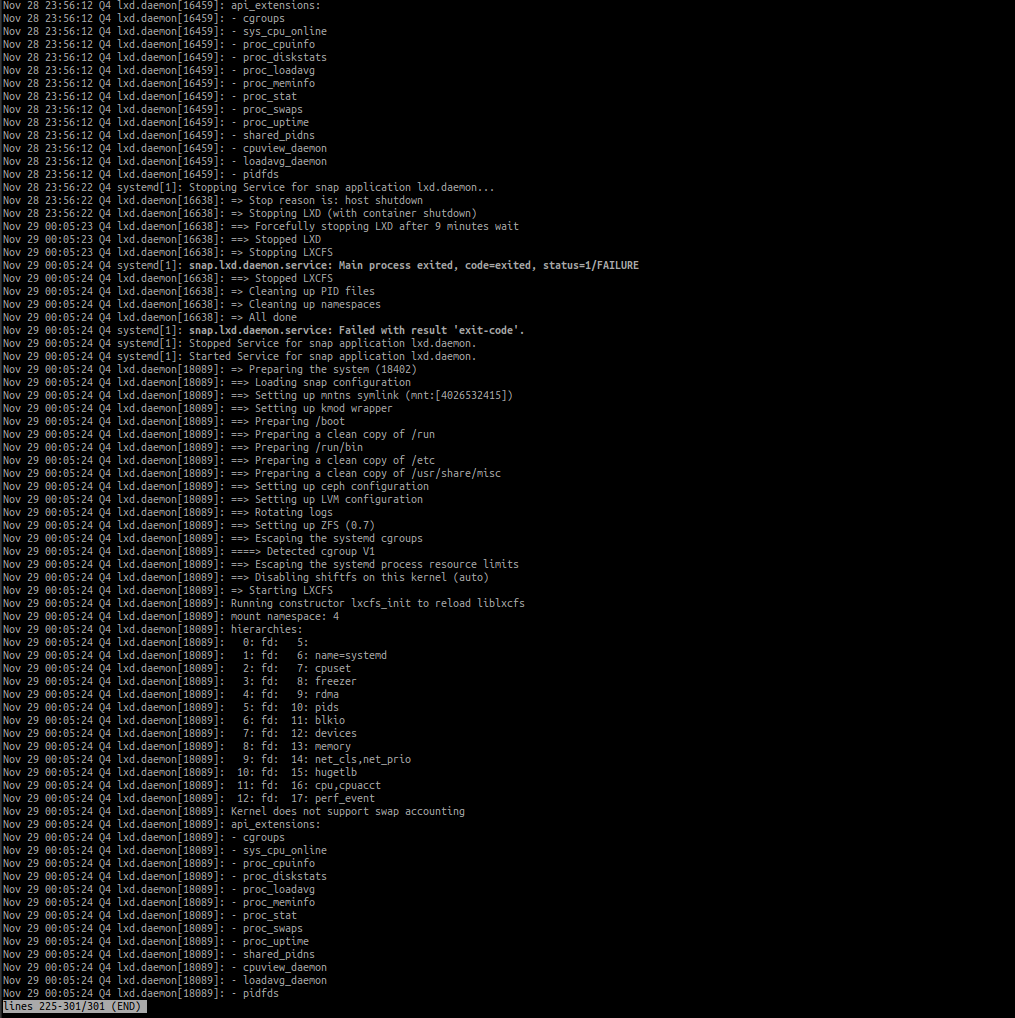
Your screenshots don’t actually show the bottom of some of the journal output so it’s hard to tell exactly what state they’re in, so just made my above comment based on the limited information visible.
One of the server does show it is using lxd 4.7 even if lxd/lxc version showed 4.8
I put it to snap refresh and seems to twirling away for many minutes
Sending separate journal file pics
Ok, on the one that’s stuck, do ps fauxww | grep lxd.*logfile to find the current LXD process and use kill -9 <PID> to kill it. That should unstick the refresh at which point they’ll all line up on the same version again and should be much happier.
Also, can you check all 3 other systems with ps aux | grep lxd.*logfile to confirm they have LXD running and just waiting for the update to go through?