Why? Can’t it go into a Read only mode and give a message … better than just stuck. In read only mode it would be nice if you can start and stop individual containers, and access them, you just can’t add or delete them. It should also be ready for a second node to come online.
I will send you log files. Anyone in particular your interested in?
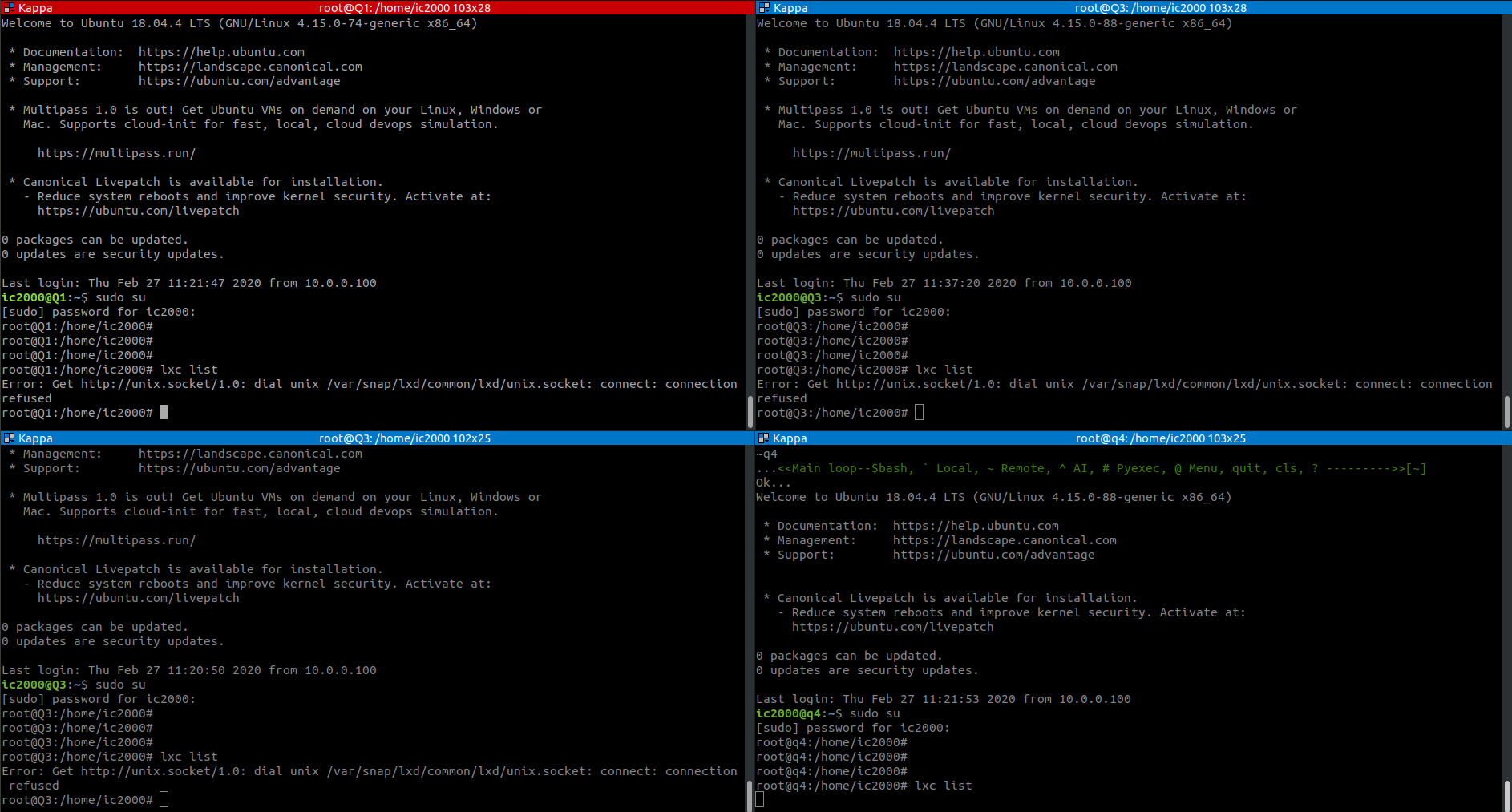
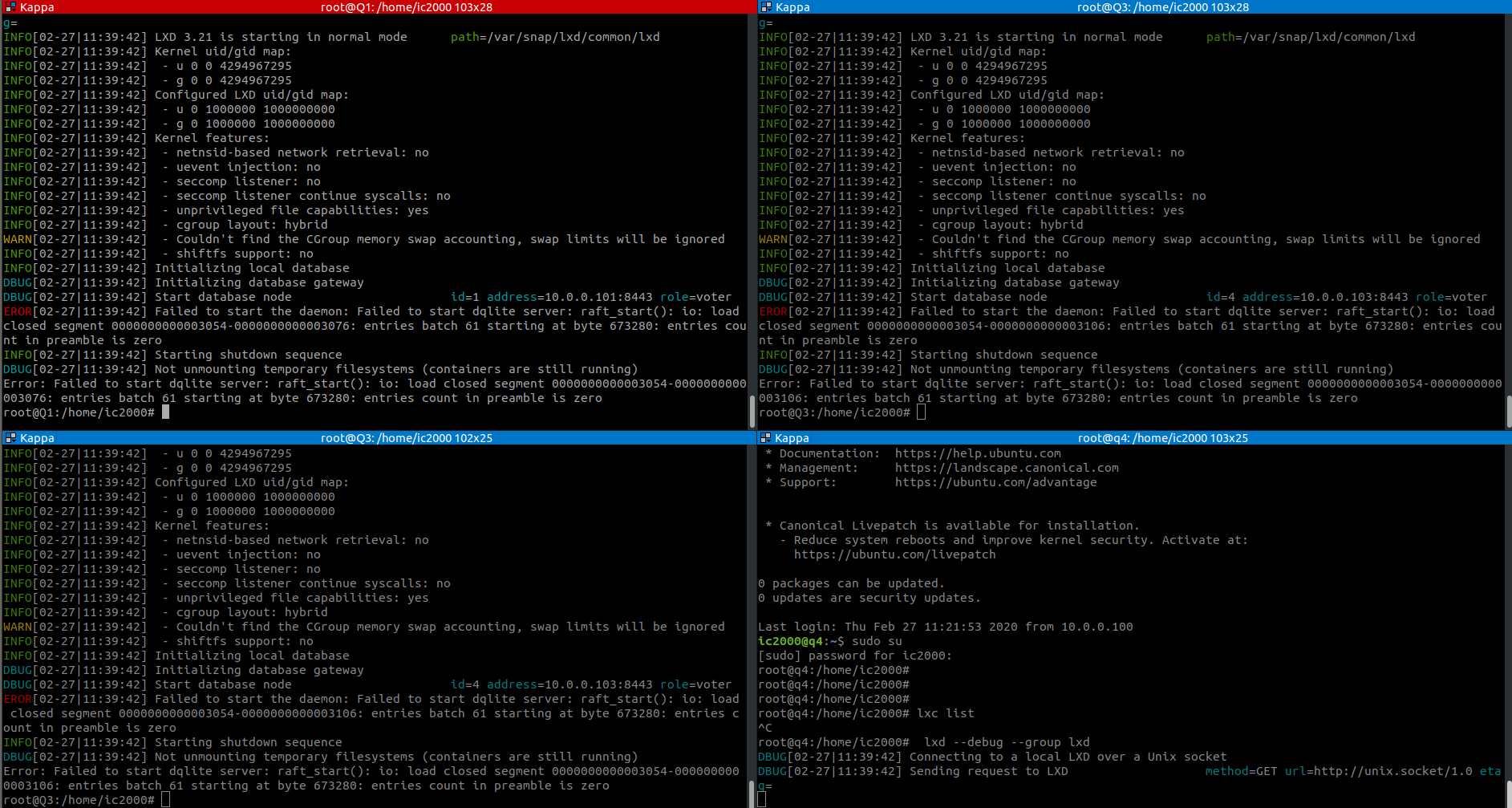
BTW, You can test this with just two machine. The problem seems to be with cluster members 1 and 2
Here is some additional info.
When you bring back the second cluster member and try to do lxc list or anything else
you get nothing, but in background
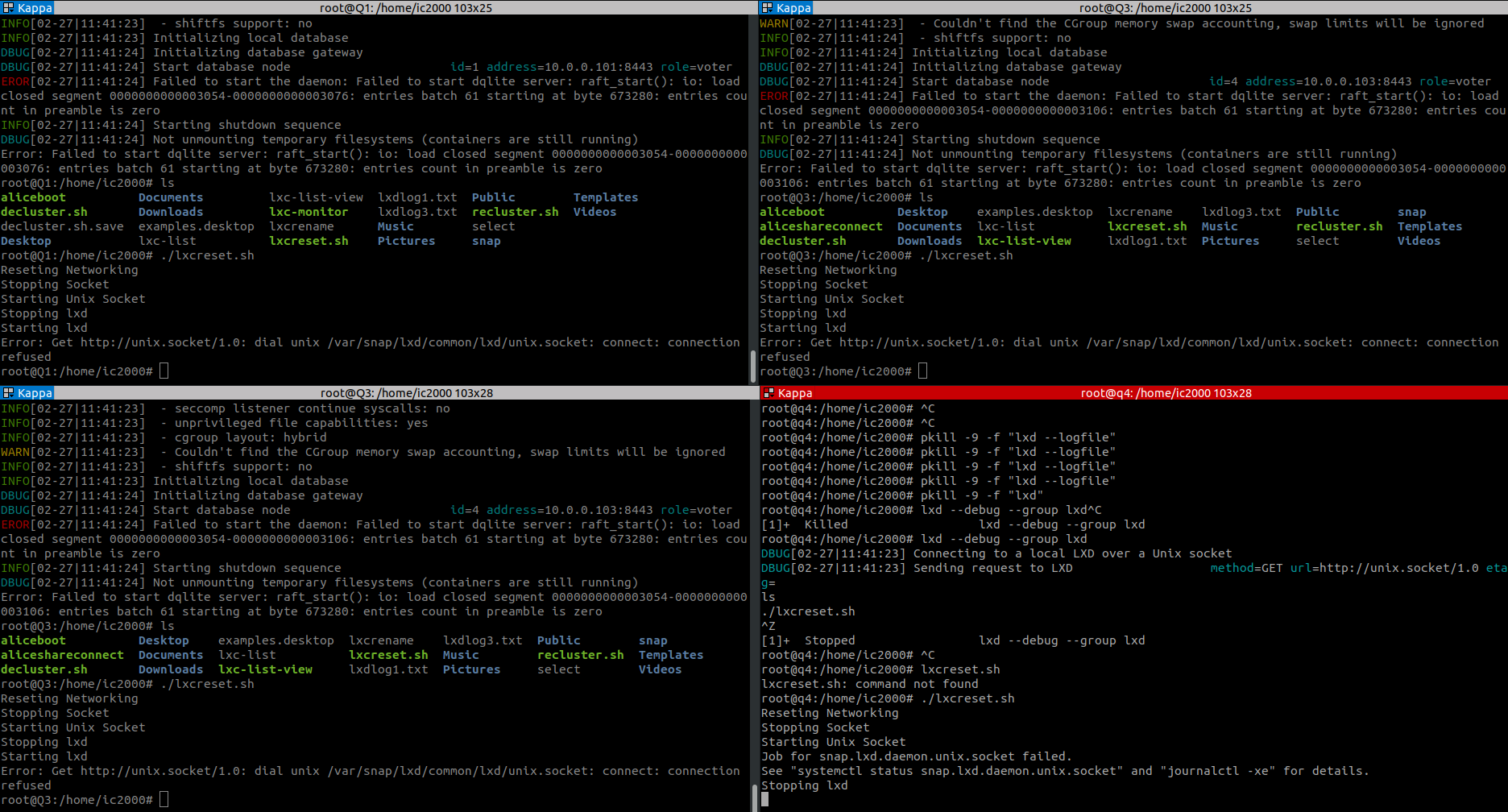
If I do the following on both machines - it gets going
root@Q0:/home/ic2000# pkill -9 -f “lxd --logfile”
root@Q0:/home/ic2000# lxd --debug --group lxd
DBUG[02-22|11:40:52] Connecting to a local LXD over a Unix socket
DBUG[02-22|11:40:52] Sending request to LXD method=GET url=http://unix.socket/1.0 etag=
DBUG[02-22|11:40:52] Got response struct from LXD
DBUG[02-22|11:40:52]
{
“config”: {
“cluster.https_address”: “10.0.0.100:8443”,
“core.https_address”: “10.0.0.100:8443”,
“core.trust_password”: true
},
“api_extensions”: [
“storage_zfs_remove_snapshots”,
“container_host_shutdown_timeout”,
“container_stop_priority”,
“container_syscall_filtering”,
“auth_pki”,
“container_last_used_at”,
“etag”,
“patch”,
“usb_devices”,
“https_allowed_credentials”,
“image_compression_algorithm”,
“directory_manipulation”,
“container_cpu_time”,
“storage_zfs_use_refquota”,
“storage_lvm_mount_options”,
“network”,
“profile_usedby”,
“container_push”,
“container_exec_recording”,
“certificate_update”,
“container_exec_signal_handling”,
“gpu_devices”,
“container_image_properties”,
“migration_progress”,
“id_map”,
“network_firewall_filtering”,
“network_routes”,
“storage”,
“file_delete”,
“file_append”,
“network_dhcp_expiry”,
“storage_lvm_vg_rename”,
“storage_lvm_thinpool_rename”,
“network_vlan”,
“image_create_aliases”,
“container_stateless_copy”,
“container_only_migration”,
“storage_zfs_clone_copy”,
“unix_device_rename”,
“storage_lvm_use_thinpool”,
“storage_rsync_bwlimit”,
“network_vxlan_interface”,
“storage_btrfs_mount_options”,
“entity_description”,
“image_force_refresh”,
“storage_lvm_lv_resizing”,
“id_map_base”,
“file_symlinks”,
“container_push_target”,
“network_vlan_physical”,
“storage_images_delete”,
“container_edit_metadata”,
“container_snapshot_stateful_migration”,
“storage_driver_ceph”,
“storage_ceph_user_name”,
“resource_limits”,
“storage_volatile_initial_source”,
“storage_ceph_force_osd_reuse”,
“storage_block_filesystem_btrfs”,
“resources”,
“kernel_limits”,
“storage_api_volume_rename”,
“macaroon_authentication”,
“network_sriov”,
“console”,
“restrict_devlxd”,
“migration_pre_copy”,
“infiniband”,
“maas_network”,
“devlxd_events”,
“proxy”,
“network_dhcp_gateway”,
“file_get_symlink”,
“network_leases”,
“unix_device_hotplug”,
“storage_api_local_volume_handling”,
“operation_description”,
“clustering”,
“event_lifecycle”,
“storage_api_remote_volume_handling”,
“nvidia_runtime”,
“container_mount_propagation”,
“container_backup”,
“devlxd_images”,
“container_local_cross_pool_handling”,
“proxy_unix”,
“proxy_udp”,
“clustering_join”,
“proxy_tcp_udp_multi_port_handling”,
“network_state”,
“proxy_unix_dac_properties”,
“container_protection_delete”,
“unix_priv_drop”,
“pprof_http”,
“proxy_haproxy_protocol”,
“network_hwaddr”,
“proxy_nat”,
“network_nat_order”,
“container_full”,
“candid_authentication”,
“backup_compression”,
“candid_config”,
“nvidia_runtime_config”,
“storage_api_volume_snapshots”,
“storage_unmapped”,
“projects”,
“candid_config_key”,
“network_vxlan_ttl”,
“container_incremental_copy”,
“usb_optional_vendorid”,
“snapshot_scheduling”,
“container_copy_project”,
“clustering_server_address”,
“clustering_image_replication”,
“container_protection_shift”,
“snapshot_expiry”,
“container_backup_override_pool”,
“snapshot_expiry_creation”,
“network_leases_location”,
“resources_cpu_socket”,
“resources_gpu”,
“resources_numa”,
“kernel_features”,
“id_map_current”,
“event_location”,
“storage_api_remote_volume_snapshots”,
“network_nat_address”,
“container_nic_routes”,
“rbac”,
“cluster_internal_copy”,
“seccomp_notify”,
“lxc_features”,
“container_nic_ipvlan”,
“network_vlan_sriov”,
“storage_cephfs”,
“container_nic_ipfilter”,
“resources_v2”,
“container_exec_user_group_cwd”,
“container_syscall_intercept”,
“container_disk_shift”,
“storage_shifted”,
“resources_infiniband”,
“daemon_storage”,
“instances”,
“image_types”,
“resources_disk_sata”,
“clustering_roles”,
“images_expiry”,
“resources_network_firmware”,
“backup_compression_algorithm”,
“ceph_data_pool_name”,
“container_syscall_intercept_mount”,
“compression_squashfs”,
“container_raw_mount”,
“container_nic_routed”,
“container_syscall_intercept_mount_fuse”,
“container_disk_ceph”,
“virtual-machines”,
“image_profiles”,
“clustering_architecture”,
“resources_disk_id”,
“storage_lvm_stripes”,
“vm_boot_priority”,
“unix_hotplug_devices”,
“api_filtering”,
“instance_nic_network”,
“clustering_sizing”
],
“api_status”: “stable”,
“api_version”: “1.0”,
“auth”: “trusted”,
“public”: false,
“auth_methods”: [
“tls”
],
“environment”: {
“addresses”: [
“10.0.0.100:8443”
],
“architectures”: [
“x86_64”,
“i686”
],
“certificate”: "-----BEGIN CERTIFICATE-----\nMIIB+D TOOK IT OUT
“driver”: “lxc”,
“driver_version”: “3.2.1”,
“kernel”: “Linux”,
“kernel_architecture”: “x86_64”,
“kernel_features”: {
“netnsid_getifaddrs”: “false”,
“seccomp_listener”: “false”,
“seccomp_listener_continue”: “false”,
“shiftfs”: “false”,
“uevent_injection”: “false”,
“unpriv_fscaps”: “true”
},
“kernel_version”: “4.15.0-88-generic”,
“lxc_features”: {
“cgroup2”: “false”,
“mount_injection_file”: “true”,
“network_gateway_device_route”: “true”,
“network_ipvlan”: “true”,
“network_l2proxy”: “true”,
“network_phys_macvlan_mtu”: “true”,
“network_veth_router”: “true”,
“seccomp_notify”: “true”
},
“project”: “default”,
“server”: “lxd”,
“server_clustered”: true,
“server_name”: “Q0”,
“server_pid”: 8691,
“server_version”: “3.21”,
“storage”: “zfs”,
“storage_version”: “0.7.5-1ubuntu16.7”
}
}
EROR[02-22|11:40:52] Failed to start the daemon: LXD is already running
INFO[02-22|11:40:52] Starting shutdown sequence
DBUG[02-22|11:40:52] Not unmounting temporary filesystems (containers are still running)
Error: LXD is already running
root@Q9:/home/ic2000# lxc cluster list
±-----±------------------------±---------±-------±------------------±-------------+
| NAME | URL | DATABASE | STATE | MESSAGE | ARCHITECTURE |
±-----±------------------------±---------±-------±------------------±-------------+
| Q0 | https://10.0.0.100:8443 | YES | ONLINE | fully operational | x86_64 |
±-----±------------------------±---------±-------±------------------±-------------+
| Q9 | https://10.0.0.109:8443 | YES | ONLINE | fully operational | x86_64 |
±-----±------------------------±---------±-------±------------------±-------------+
IT WORKS AFTER A KICK