Or for some reason your lxd binary is actually the lxc one. Please check md5sum /usr/bin/lxc and md5sum /usr/bin/lxd. You need to run lxd, not lxc.
root@LARRY:/home/ic2000# md5sum /usr/bin/lxd
e72892bc83af63d0cc41fb4213b706b4 /usr/bin/lxd
root@LARRY:/home/ic2000# md5sum /usr/bin/lxc
2ebc2324ae1edde8c80d9ba6e870c2f0 /usr/bin/lxc
root@CURLYJOE:/home/ic2000# md5sum /usr/bin/lxde72892bc83af63d0cc41fb4213b706b4 /usr/bin/lxd
root@CURLYJOE:/home/ic2000# md5sum /usr/bin/lxc2ebc2324ae1edde8c80d9ba6e870c2f0 /usr/bin/lxc
On curlyjoe systemctl stop lxd isn’t really stopping lxd, since I can see the process in the ps aux output.
Perhaps systemctl kill lxd might help. @stgraber do you have suggestions for how to kill the systemd unit process entirely? I seem to remember having problem to do that in the past.
@Tony_Anytime you need to completely kill the lxd process on curlyjoe, then try to start it again by hand with lxd --verbose --debug and do the same on larry.
Those in Curlyjoe are running containers, I can always reboot it. But then if it doesn’t come up, then my containers are all dead
I can manually kill all the process one by one in larry
Got larry clean
root@LARRY:/home/ic2000# ps aux | grep lxd
root 5058 0.0 0.0 14428 1000 pts/0 S+ 14:58 0:00 grep --color=auto lxd
On curlyjoe you don’t only have containers, you also have a stuck lxd waitready process:
root 20961 0.0 0.0 529476 18900 ? Ssl 14:32 0:00 /usr/lib/lxd/lxd waitready --timeout=600
and daemon:
root 17142 0.0 0.0 529732 18940 pts/12 Tl 14:29 0:00 /usr/lib/lxd/lxd --verbose --debug
although the latter might be the one you started by hand.
the lxd waitready --timeout=600, I kill it and it comes back.
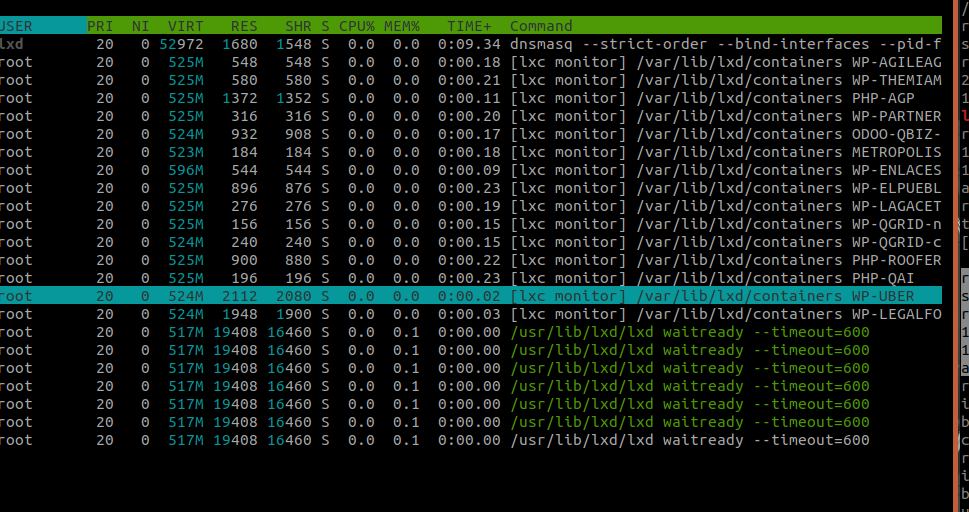
Yeah that’s the problem with the systemd unit I think, waitready keeps getting respawned. Let’s wait for @stgraber and see if he has suggestions.
Yeah, I read somewhere this version of LXD has a problem with this, that is one reason trying to get away from it.
Got it with systemctl stop lxd.socket lxd.service
What’s the output of ls /var/log/lxd/database/global on curlyjoe? Assuming that the data on larry is healthy and the only problem is that it can’t find other peers, then you should wipe the database/global directory on curlyjoe and restart lxd.
I am not at my computer for a while now, I will check on this as soon as I get back , would be in about an hour.
What is the best procedure to start Larry and then get curlyjoe going. I have done this a few times but it seems they’re not talking to each other blocking the port. Is there anything I can do to test the communication between the two server something like a telnet.
If larry is able to start without crashing, then delete the database/global directory from curlyjoe and retry.
Hm, did you remove only database/global from curryjoe or also database/local.db? You have to remove only database/global, and database/local.db must stay. If you did not touch database/local.db, then there might be some other problem: you can try copy the database/global directory from larry to curryjoe and retry.
Yes, only global. Larry does not seem to want to come up, it wants to find any of the peers, is that normal? I am can copy global directory to cj.
I can’t believe there is no way to uncluster a server. Turn it back to stand alone.
1 Like
Any ideas on getting Larry started
I upgraded from lxc to lxd and I understand why you are confused.
Lxd has one point of failure and it is its database. When it does not run or was unexpectedly closed (not your case ) lxd cannot run.
And what is much more sad, in most cases you want be able to fix it by yourself.