Yes thats right. There is a lightweight daemon that is part of the snap package that uses a dqlite clustered database for controlling and configuring ceph components.
If you want to connect an external LXD that isn’t running on the same host(s) as MicroCeph then you need to copy the ceph.conf and ceph.client.admin.keyring files from /var/snap/microceph/current/conf from one of the MicroCeph host(s) to your local LXD system(s) into /etc/ceph.
This isn’t required when using the LXD snap package on the same host(s) as the MicroCeph installation because the LXD snap has detection for MicroCeph built-in:
Also required for LXD to operate ceph storage pools on MicroCeph is to run the following command on one of the MicroCeph hosts:
microceph.ceph config set mon mon_allow_pool_delete true
I’ve found this useful for using MicroCeph when running the LXD test suite locally to test the ceph storage driver.
Is it possible at all to change an IP address of a ceph node after completing the init? I have a playfield installation with three (old) PCs. I forgot to give all three a fixed IP address.
Is there a way to change the IP address in the ceph config?
If not, how can redo the installation? Perhaps just snap remove --purge?
Currently there’s no way to handle re-addressing, so you’d indeed need to go the purge route for the time being.
I think we’ll eventually want to allow it, but it’s a bit tricky as we need to reconfigure both microceph itself and the ceph deployment too, including all of its clients.
Love what you guys are doing 
I’ve encountered an issue after I rebooted each host and now one of the osd’s is down. I can find a way to stop osd’s, but not bring them back up. Rebooting has not helped, and I tried reloading the snap microceph service as well. I’m not hugely familiar with ceph, so it might be obvious to someone else.
I’ve found this in my journalctl
microceph.daemon[5691]: time="2022-12-11T12:46:30Z" level=error msg="Failed to send database upgrade request" error="Patch \"https://10.10.101.43:7000/cluster/internal/database\": Unable to connect to: \"10.10.101.43:7000\""
I don’t have any firewalls active on these hosts, so shouldn’t be something as simple as this. It’s just a 3 pool cluster, 3 drives, and 2 of them are healthy.
Ah, glad I’m not the only one ![]()
Please could you post more details there to help figure out what’s going on?
No problem, I shall see you on the other side
I assume its on the roadmap, but having a preseed option for this tool would be great for a lab env.
What does it mean that storage is PENDING after adding ceph storage?
I didn’t quite start with a totally new lxd installation. I already had one to play with. I did the setup of microceph. It is running. Now I wanted to add a storage ceph as follows:
$ sudo lxc storage add ceph ceph
Error: Pool not pending on any node (use --target <node> first)
So I selected one of the three nodes.
$ sudo lxc storage add ceph ceph --target kwistbeek
Storage pool ceph pending on member kwistbeek
Now the ceph storage is in state PENDING. What do I have to do next?
Hi @kees ,
Take a look at those links.
https://www.youtube.com/watch?v=PX1n3ZAWuAU&t=391s
https://linuxcontainers.org/lxd/docs/master/howto/cluster_config_storage/
Regards.
Hope you’ve all had a Merry Xmas 
I’ve not been able to add to an existing LXD cluster either. I always ended up in pending or error (while guessing) state as well. I did try the above method, but also did reach out to Stephane in the youtube video, but LXD doesn’t automatically pick up the cluster with this command…
systemctl reload snap.lxd.daemon
I’ve tried this…
lxc storage create ceph1 ceph --target uby2
lxc storage create ceph1 ceph --target uby1
lxc storage create ceph1 ceph --target uby3
sudo microceph.ceph osd pool ls
output:
.mgr
lxc storage create ceph1 ceph ceph.osd.pool_name=.mgr
output:
Error: Failed to run: rbd --id admin --cluster ceph --pool .mgr --image-feature layering --size 0B create lxd_.mgr: exit status 95 (2022-12-26T14:25:07.411+0000 7f34ee7fc700 -1 librbd::image::CreateRequest: 0x55650799f480 handle_add_image_to_directory: error adding image to directory: (95) Operation not supported
rbd: create error: (95) Operation not supported)
I am obviously guessing with the above commands to try & make it work, and I did try with the id value from microceph.ceph status, but I get the same error. So it’s not obvious from documentation how to add to an existing lxd cluster… probably more so with my limited skillset with ceph.
I am experiencing issue 71 on the github repo which is probably not related but, thought i’d mention just in case.
Enjoy the rest of your festivities
I think there is a bug in latest microceph snap, We have the same issues here Introducing MicroCloud - #16 by stgraber
Some early issues with MicroCeph have been fixed today and both MicroCloud and MicroCeph have been updated.
If you’ve had any issues with either of the projects, please give them another try!
Specifically, this fixes issues with rbd create as well as the reported I/O error in microceph.ceph status which was related. Basically there was an issue with module loading within the OSD daemon which would prevent the creation of RBD images but would not otherwise prevent Ceph from starting up.
I checked today and confirm that issue with rbd create has been resolved, thank you very much. i am looking forward to further testing.
I can verify this works for me as well, thank you
Following along with the specific instructions in the video, I now get this when trying to initialize LXD after getting microceph running:
Error: Failed to create storage pool “remote”: Failed to run: ceph --name client.admin --cluster ceph osd pool create lxd 32: exit status 1 (Error initializing cluster client: ObjectNotFound(‘RADOS object not found (error calling conf_read_file)’))
Is it because ceph-common is not installed as part of the microceph snap?
root@lab1:~# microceph.ceph status
cluster:
id: fd84322b-2715-4975-8edf-cc4248e04f45
health: HEALTH_OK
services:
mon: 3 daemons, quorum lab1,lab2,lab3 (age 28m)
mgr: lab1(active, since 30m), standbys: lab2, lab3
osd: 3 osds: 3 up (since 28m), 3 in (since 28m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 577 KiB
usage: 65 MiB used, 750 GiB / 750 GiB avail
pgs: 1 active+clean
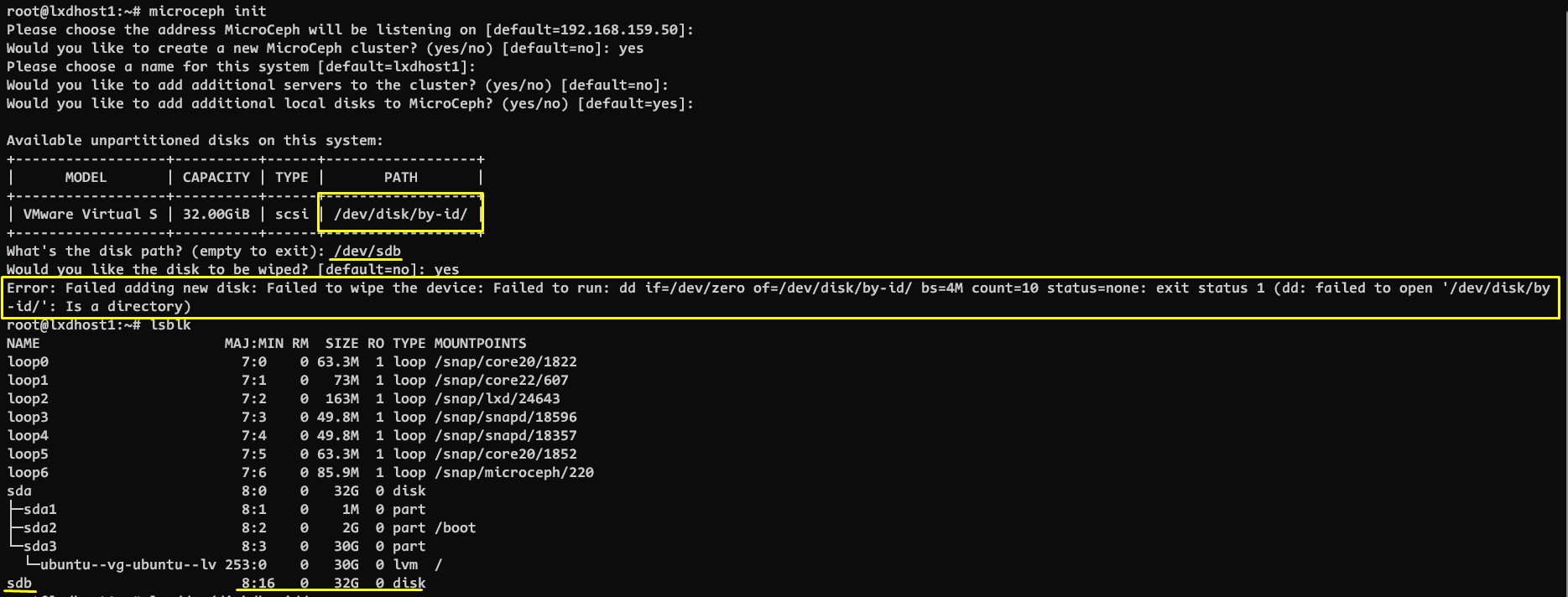
It would appear that you can’t use a raw unformatted disk. It seems that the path to the disk to be used for the OSD can only be from the “/dev/disk/by-id/” path. If I provide the simple “/dev/disk” path, then the OSD cannot be added. Raw unformatted disks do not have an “ID” that can be referenced in the path of “/dev/disk/by-id/”. Is there a reason that you can’t just use a “/dev/disk” path? Why only allow the specific path of “/dev/disk/by-id/”?
Hmm, I thought we fixed that particular bug a couple weeks ago. Could you try with the edge channel of microceph?
We need to promote a full suite of microceph, microovn and microcloud snaps as soon as the new snapd is finally in stable…
Hello Stéphane,
Before starting the Micro Cloud setup, do we need to add all the nodes to an LXC cluster? Is that a pre-requisite for micro cloud ( and LXD) to detect the servers to be added to micro cloud cluster.
No, MicroCloud will configure LXD into a cluster.