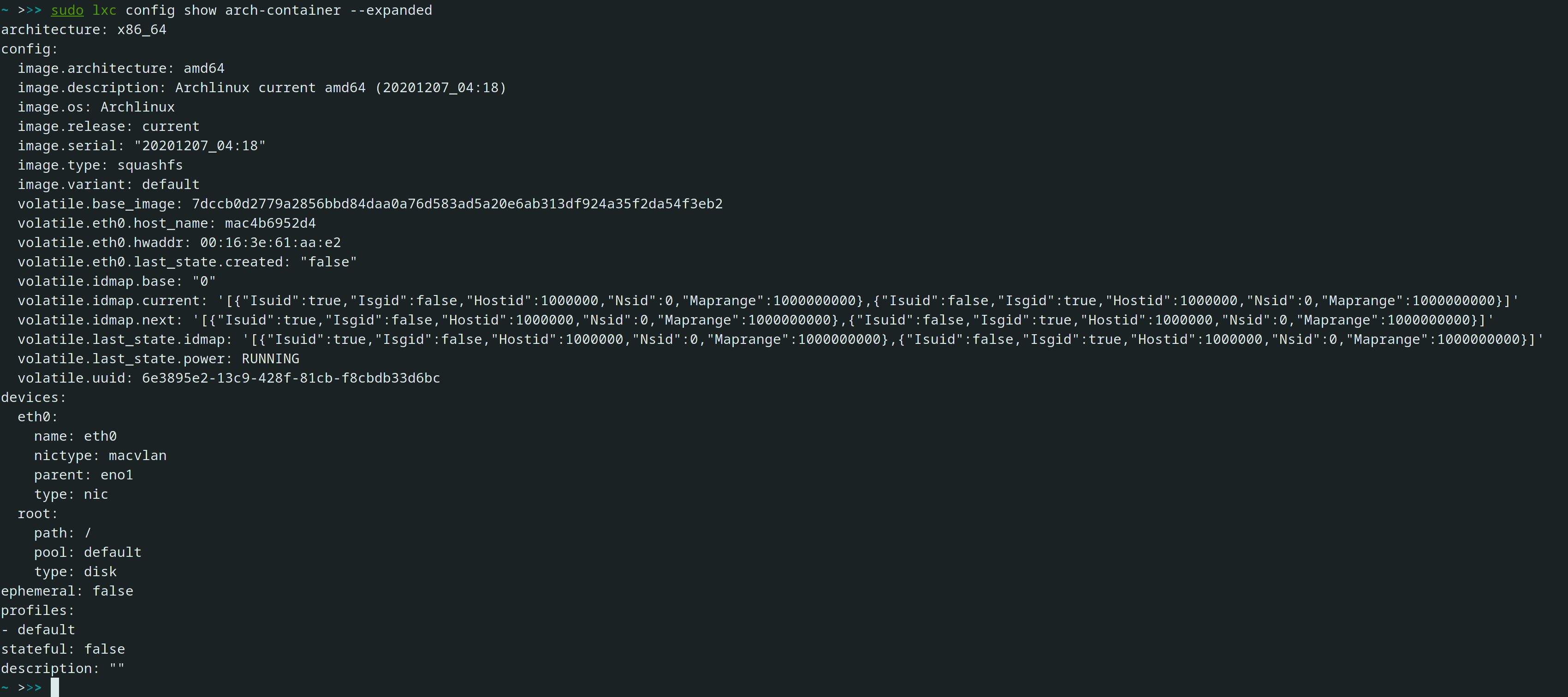
While I’m not a LXD dev and you should take my advice with a pinch of salt, I’d say probably no. I don’t see how making something readonly instead of readwrite could be a security risk. If anything, it could remove existing capabilities of container. I only tested a dnf installation, maybe there are some stuff that will break.
probably no. My impression is that the proper fix could be to make udev work correctly inside the container instead of forcing it to be ignored at the link creation.
From what I have seen on the net, docker is doing this mount ro and that’s why systemd has done this hideous change that I have tried to work around so the issue is muddy.
Well not the mud is getting deeper, the origin is the same for arch and fedora (and probably other distros as well). The commit text is trying to say that the goal is to disable udev in containers. So making lxc config conform to the systemd change is having the unfortunate side-effect of disabling udev, that is, if one is plugging an Usb device to the physical computer a running container will never see it.
A guess could be that is the very reason (enabling udev) for lxc to mounting /sys read-write contrary to the explicit instructions of the Book of SystemD, see Execution Environment …,
Just wanted to give an update in this thread as we now think we fully understand the problem.
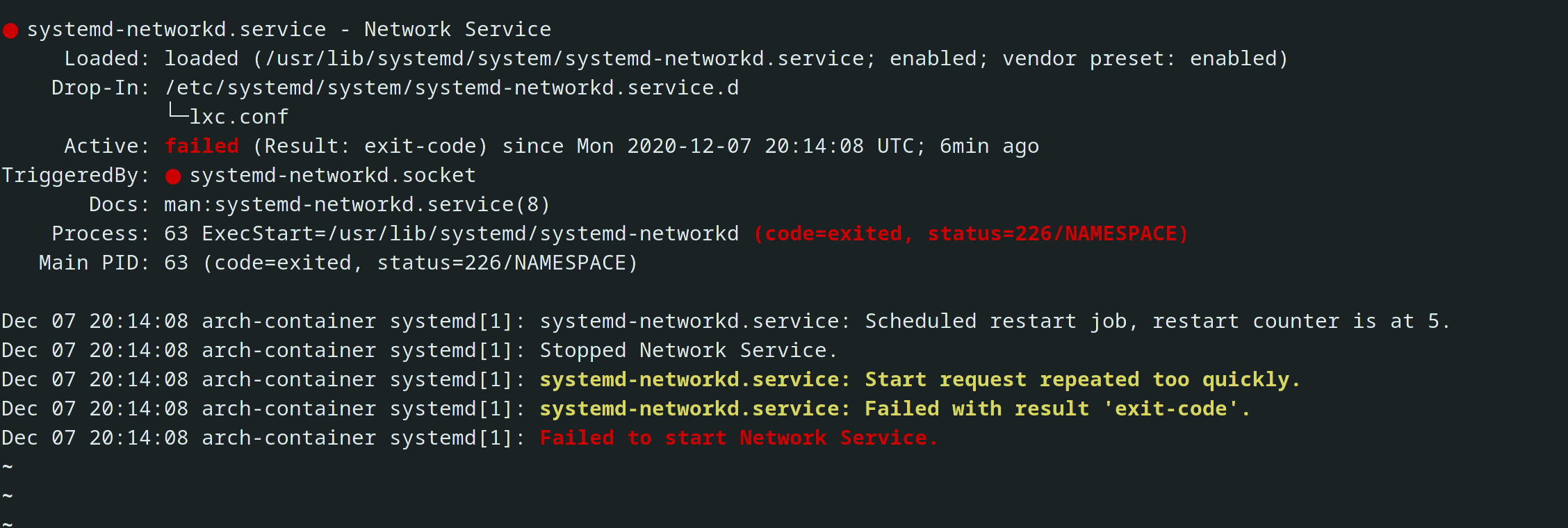
The regression was indeed introduced through a bugfix in systemd 244.1 as linked in the post above.
The systemd developers refused to back this change to fix our users arguing that the new logic is correct and that the problem is that /sys is writable in our containers.
We can’t make /sys read-only as we specifically need it writable for a number of other network operations (bridges for libvirt and the like). We also care about having udev running in containers to handle our device hotplug logic for which we’ve done kernel work in the past few years.
So this gets us in a bit of a stuck situation as far as easy fixes are concerned. We have identified one kernel issue which prevents udev from behaving in the way networkd expects it and @brauner is working on fixing this upstream, though as with any kernel change, this will take time to roll out to all distros.
The issue can be worked around a few other ways in the mean time:
Have individual distros revert the systemd change (we will push for Ubuntu to do that)
Use raw.lxc to force /sys to be read-only (as suggested above)
Use a systemd override on the systemd-networkd unit to give it a read-only /sys
It’s that last option we’re now investigating for our own images. The plan is to ship a very small systemd unit override in all affected images to make networkd behave as it did previously. Once our kernel change is widely available, this workaround can then be removed.
Did this issue break very recently in Fedora/Arch again? I Have been deploying containers on my test cluster with fan networking, and recently Fedora and Arch containers have not been getting ipv4 addresses, even if I launch with -c security.privileged=true
Any tailwind on this? Strangely, am getting the same problem on a Debian host with Ubuntu 20.04 guest. The guest has an ipv6 address but no ipv4. I’ve got two profiles, a macvlan profile and a default profile. Default profile has not been able to allocate ipv4 to the guest.
This is cross-posted from here to make it clear the same workaround applies here too.
Anyone like myself stumbling across this topic after a similar issue cropped up back in early December 2020, I can confirm that the advice in this comment on another topic about setting security.nesting=true still applies today with LXD 4.x, unprivileged containers, and the latest:archlinux image, e.g.