Thank you for all the answers. All things considered I find it a bit disappointing that a super powerful and sophisticated solution such as LXD is being delivered in a way that is rather OPS and IaC unfriendly. The recommended way lacks repeatability and fine grained control of security update cycles.
We will probably move along the following lines:
repeatability: we are forced to accept that installations are not repeatable which therefore will force a full test every time we deploy a new cluster or standalone server; the corresponding effort will be reflected in couple of ways over time, rather then in planned feature update cycles
control of updates: we will implement a workaround that prevents automatic updates, probably based on the suggestions written here:
and share the results with the community.
Problem 1) would be easily fixed if older channels were kept for a reasonable amount of time. On the replies written here, there seems to be an implicit assumption that OPS teams will not do “the right thing” if they are not forced to, “the right thing” being updating their system once updates are available. Because “the right thing” depends on risk/benefit analysis which is particular to each project where lxd is used, I find this "one fits all " assumption a bit too radical. It kind of says that the security risk from not updating immediately is always higher than the risk of unpredictable behaviour on a production system, arising from slight differences in the software. My experience with risk analysis tells me that it really depends on the exposure and impact, among other things.
Problem 2) is a serious design problem with snap not related to lxd. It needs to be fixed, unfortunately by means of workaround, for any critical infrastructure component that is delivered this way.
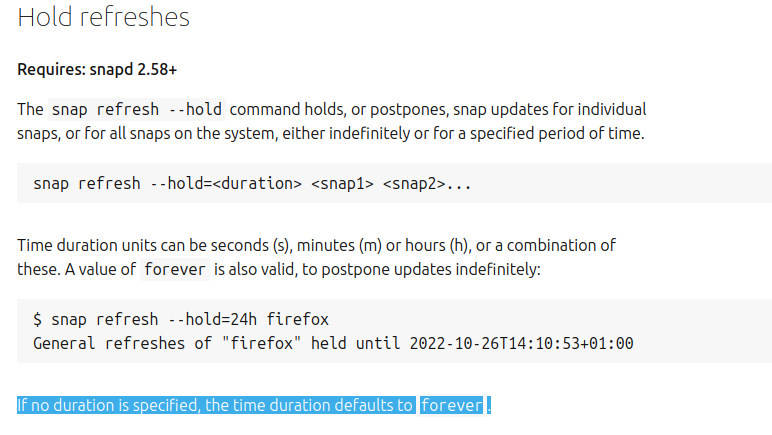
On that point, snapd does support the ability to defer updates for up to 60 days and also specify the times when these updates occur, so it doesn’t have to be immediately updated as the software is released.
Also, note, that LXD clusters all have to run the same LXD version, so they should be updated together close after one and other (irrespective of whether using snap or not).
The point of immediately here was about being forced to adopt newer versions on fresh installs almost after they are released (only an older one is kept). This assumes that OPS teams will always be wrong in their management, that they must be forced to use the latest or they will never update.
In the context of snap refreshes, 60 days being reasonable is also an assumption. Whether 60 days is too much or too little depends on the context. In the blog article I linked above a former Snap Advocate of Canonical, includes a cron job that postpones the refresh everyday in order to not have a deadline. I guess that it says a lot.
I am aware of Snap Proxy - it just seems to me contra natura to have to do that. It also introduces other potential problems.
Also, note, that LXD clusters all have to run the same LXD version, so they should be updated
together close after one and other (irrespective of whether using snap or not).
I would like to do a gentle follow up in the matter of reproducibility and immutability of the installations. The workaround above seems to not work with the latest LXD snap and the need for reproducible and immutability of the installations remains. Can you advise?
We’d like to install an LTS version of LXD and make sure it never gets updated automatically (we will manage the updates in the right moments). Previously an unnelegant workaround was necessary (see above).
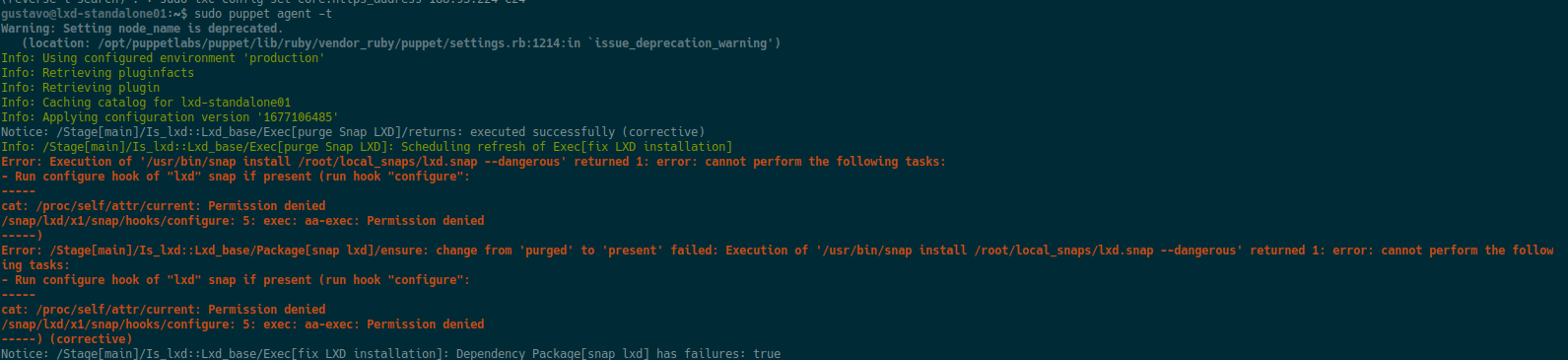
Seems that without the --dangerous option (which worked before and now does not…) we also need to run snap ack. However it seems that by running this we are enabling automatic refreshes to be performed which defeats the purpose of this exercise.
As a matter of fact a Snap refresh just killed one of our existing test LXD servers that had been installed with snap ack by updating from 4.x stable to 5.x (VM terminal access stopped working)
This is breaking business continuity for serious users of LXD - we simply can’t have production servers updated in an uncontrolled manner. I am aware of the SNAP proxy but that adds unnecessary complexity - the point is running a reliable virtualization server, not a server that workarounds SNAP problems.
Would you be able to suggest a simple solution to not have our LXD servers updated except when we want to?
due to the confusion introduced by the change of snap behaviour (inside an LTS version!) we had two machines that took unintended LXD upgrades (from 4.0.X to 5.12) and plus interruption of running production systems
After the unintended upgrades to 5.12 we can’t downgrade even to 5.0.X because the lxd recover command does not recognize the machines. On version 5.12:
sudo lxc exec my-vm bash
fails with
Error: Failed to connect to lxd-agent
This worked 100% before the upgrade. I tried to upgrade lxd inside the VM but that did not work either. Any ideas on how to solve?