Hello,
First, not sure if LXC is the right Topic. I am using LXD, but since its related to performance, in my mind, it’s a LXC question …
From what I observed, using LXC add some overhead in I/Os, leading to higher cpu wait and load on machine. I was wondering if I was doing something bad, or if it was expected. A small plan for my post:
- My test case
- Control machine
- LXC configuration
- Results
- Weird configurations
- Questions
My test case
In my case, I test LXC with a NoSQL database (LSM tree under the hood, therefore, lots of I/Os). I wanted to see whether performance were equivalent using 2 containers on 1 machine (each of the containers running one node of the database), or directly deploying the 2 nodes on the machine (better use of our hardware when deploying 2 nodes).
+--------------+-------------+
| NODE2 | NODE1 |
+--------------+-------------+
| CONTROL MACHINE |
+----------------------------+
+--------------+-------------+
| NODE3 | NODE4 |
+--------------+-------------+
| LXC | LXC |
+--------------+-------------+
| TEST MACHINE |
+----------------------------+
For my test, we have 2 exact identical machines. In order to test the behaviour in each configuration, we start the 4 nodes on the 2 machines, and make them form a unique cluster.
To make sure that both machine manipulate the exact same data, we have to:
- define one replica for all collections;
- prevent a replica set to be define on the same machine as its primary set.
Control machine
The control machine runs on a CentOS 7 (Kernel 3.10.0). When pushing data on the cluster, we push everything on this machine (then, it dispatchrd data to the second machine with LXD). The filesystem is XFS.
LXC configuration
For the LXC configuration, we use default parameters (therefore no limits on I/O, nor write, etc). LXC also writes on XFS.
+--------------+-------------+
| NODE3 | NODE4 |
+--------------+-------------+
| LXC | LXC |
+--------------+-------------+
| XFS | XFS |
+--------------+-------------+
| LOGICAL VOLUME |
+----------------------------+
| TEST MACHINE |
+----------------------------+
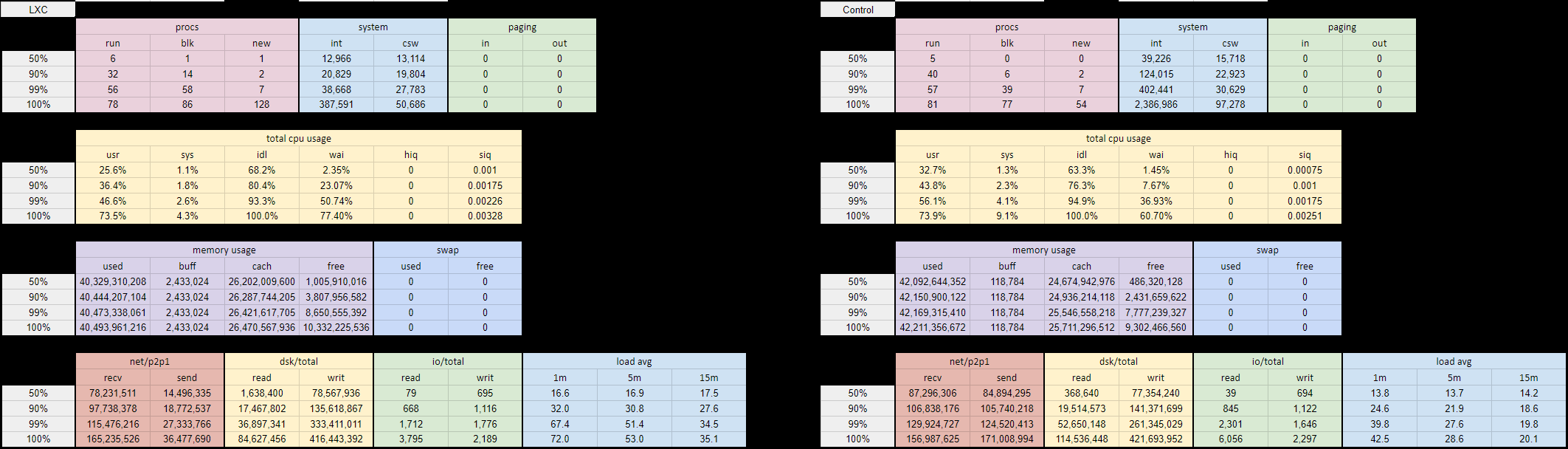
Results
The results are consistent through multiple tests:
- CPU wait much higher on the machine with LXC (from 1.3% to 7.7% in median, and from 4.9% to 23.8% for percentil 90);
- load average is 50% higher;
- IO read are higher for median and percentile, but lower for max values).
Weird configurations
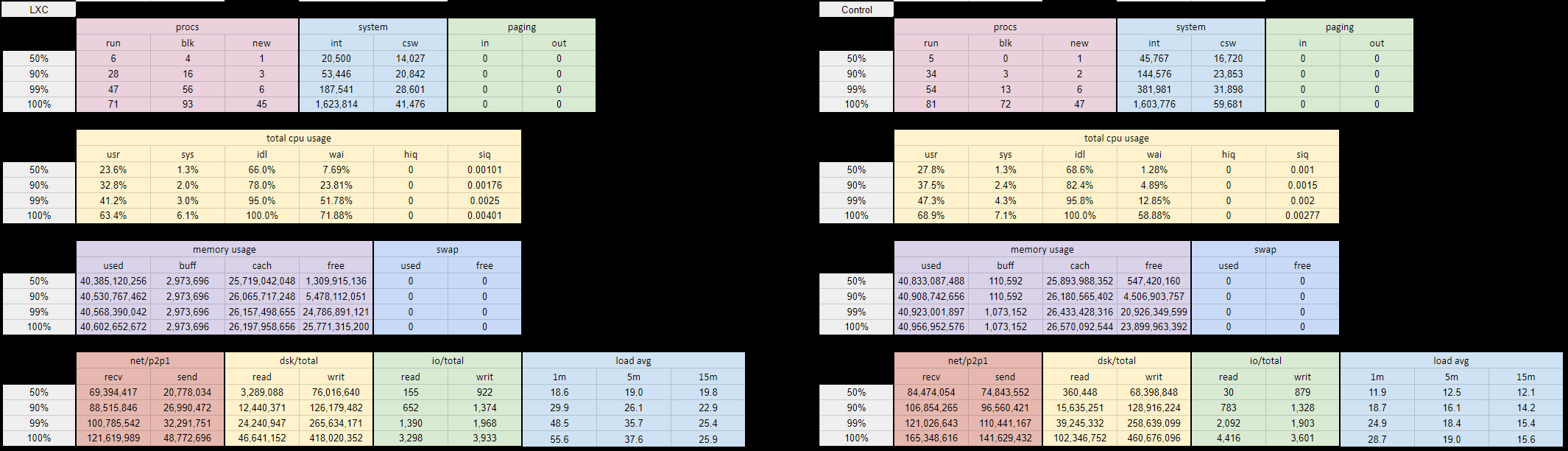
Seing this, we ran 2 additional tests:
- Instead of running 2 nodes inside 2 different container, we run them inside the same container.
Results are pretty similar to the previous test (image in next post). - we run the 2 nodes outside of the LXC containers (but for some reason, we still write on the XFS defined for the containers).
I/Os are equivalent to the test when using no LXD (image in next post).
For me, this result shows that the filesystem configuration with the logical volume is not the issue.
Questions
- Is it expected to have such a behaviour with I/Os while running inside a container ?
- Are there any parameters we could check/tweak to get better performances ?