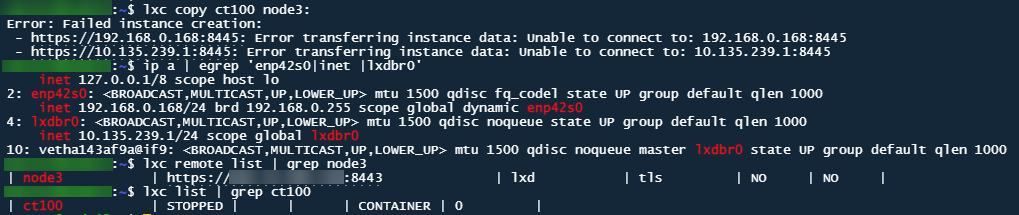
the node in question is setup to listen on 8445. I know the issue is with the receiving node, because I cannot copy from a 3rd node to node3 either.
PS: node 3 has had it’s hostname changed, and the remote was renamed. since i was still having problems, i removed/readded the remote under the new hostname (and I am still having the same problem). The client remote (the local one) has not had its hostname changed.
All machines are running the LXD/LXC current to Ubuntu Focal LTS.
The way LXD works is that it tells your target server (node3) to connect to wherever ct100 is stored, this seems to not be working in your case.
You can try passing --mode=push to reverse the direction or use --mode=relay to have your CLI tool relay all the migration data between source and destination.
--mode=relay works, but it is terribly slow. --mode=push also works, and it is also very slow.
would --mode=pull possibly be even faster?
is the default pull not working because of double NAT (the lxd bridge NAT, and the NAT from the router behind which this machine sits)? or is it because the machine does not have a public IP? the LXD ports 844x are all properly forwarded at the router. On the machine firewall i have an UFW rule opening specifically to the LXD instance external to the LAN (the source machine is in my LAN. the target machine has a public IP at a DC and firewall with 8443 open to any IP)
the driver on all storage is DIR, and DIR is on LVM/ext4. I have to use DIR to get the maximum performance from the disks.
Speed should be identical between pull and push, it can be slower in relay if relaying through a 3rd system on a slow link.
In your case, LXD will run rsync over the LXD API and transfer all of the data that way.
Given you’re using the dir backend, I’m hoping you don’t have snapshots as that would be very very expensive. You may also want to check that you don’t have rsync.bwlimit set on either the source or target storage pool as that would slow down your transfer.
lxc storage get default rsync.bwlimit returns nothing on both source and target.
rsync.compression is set to false but changing this did not improve transfer speed, as the bottleneck is not the bandwidth (we should be getting at least 10MB/s. local transfers are 110MB/s as they should since the network limit is ~125MB/s, or 1 Gbps). speedtests on these machines regularly get between 500Mbps and 850Mbps symmetrical
I am trying to copy stopped instances, not their snapshot. Which BTW, we have no need for snapshots. they are not reliable as the contents on disk change way too fast (it’s a constant write DB, and despite atomicity cannot be reliably snapshotted at any point you desire).
Reversing the path (switching source/target) for a copy operation brings decent speeds (at least 15MB/s). But copying from the external LXD machine, the one with the public IP, using the LAN machine instance as source lxc copy lan-machine:container container yields the same slow speed as lxc copy container wan-machine:container
netstat -i on the LAN machine shows increasing RX-DRPs on the physical adapter, no other non OK number goes up. The other interfaces are clean.
not sure what to do next. the default mode never worked, i had to use push since forever, but it’s never been this slow.
I did some further testing, and the upload speed using iperf to the WAN machine is indeed as lxc copy runs. Using the -p 10 switch, to use multiple iperf streams, increases the speed by 10x.
Is there a switch to use multiple streams for the copy operation? It is beyond the scope here why multiple streams increase the throughput.