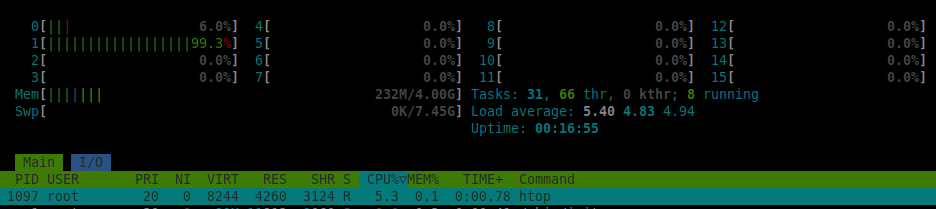
As this happened on a production machine, I had to quickly revert to backup and keep the container on Bullseye. CPU limits work fine there.
However in my test lab I can also reproduce the same behaviour on an older (Debian 10 Buster) LXC Host with LXC 3.0.3 (installed through Debian repos).
root@lab ~ # grep cgroup /var/lib/lxc/bookworm/config
/var/lib/lxc/bookworm/config:lxc.cgroup.cpuset.cpus = 6-7
/var/lib/lxc/bookworm/config:lxc.cgroup.cpu.shares = 1024
/var/lib/lxc/bookworm/config:lxc.cgroup.memory.limit_in_bytes = 4G
After starting the bookworm container, memory limit (4G) is correctly working:
root@bookworm:~# free
total used free shared buff/cache available
Mem: 4194304 237008 3720092 3036 237204 3957296
Swap: 7811068 0 7811068
root@bookworm:~# cat /sys/fs/cgroup/memory/memory.limit_in_bytes
4294967296
But CPU limit is “ignored”:
root@bookworm:~# grep cores /proc/cpuinfo
cpu cores : 8
cpu cores : 8
However the cgroup limit inside the container seems to be correct:
root@bookworm:~# cat /sys/fs/cgroup/cpuset/cpuset.cpus
6-7
Hmmmmm 
Differences in /sys/fs/cgroup/:
Debian 11:
root@bullseye:~# ll /sys/fs/cgroup/
total 0
-r--r--r-- 1 root root 0 Nov 20 17:00 cgroup.controllers
-r--r--r-- 1 root root 0 Nov 20 17:00 cgroup.events
-rw-r--r-- 1 root root 0 Nov 20 17:00 cgroup.freeze
-rw-r--r-- 1 root root 0 Nov 20 17:00 cgroup.max.depth
-rw-r--r-- 1 root root 0 Nov 20 17:00 cgroup.max.descendants
-rw-r--r-- 1 root root 0 Nov 20 16:59 cgroup.procs
-r--r--r-- 1 root root 0 Nov 20 17:00 cgroup.stat
-rw-r--r-- 1 root root 0 Nov 20 17:00 cgroup.subtree_control
-rw-r--r-- 1 root root 0 Nov 20 17:00 cgroup.threads
-rw-r--r-- 1 root root 0 Nov 20 17:00 cgroup.type
-rw-r--r-- 1 root root 0 Nov 20 17:00 cpu.pressure
-r--r--r-- 1 root root 0 Nov 20 17:00 cpu.stat
drwxr-xr-x 2 root root 0 Oct 5 21:44 dev-mqueue.mount
drwxr-xr-x 2 root root 0 Nov 20 17:00 init.scope
-rw-r--r-- 1 root root 0 Nov 20 17:00 io.pressure
-rw-r--r-- 1 root root 0 Nov 20 17:00 memory.pressure
drwxr-xr-x 20 root root 0 Nov 20 16:39 system.slice
drwxr-xr-x 2 root root 0 Oct 5 21:44 user.slice
Bookworm:
root@bookworm:~# ll /sys/fs/cgroup/
total 0
drwxr-xr-x 2 root root 0 Nov 20 16:48 blkio
lrwxrwxrwx 1 root root 11 Nov 20 16:48 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 Nov 20 16:48 cpuacct -> cpu,cpuacct
drwxr-xr-x 2 root root 0 Nov 20 16:48 cpu,cpuacct
drwxr-xr-x 2 root root 0 Nov 20 16:48 cpuset
drwxr-xr-x 6 root root 0 Nov 20 16:48 devices
drwxr-xr-x 2 root root 0 Nov 20 16:48 freezer
drwxr-xr-x 2 root root 0 Nov 20 16:48 hugetlb
drwxr-xr-x 6 root root 0 Nov 20 16:48 memory
lrwxrwxrwx 1 root root 16 Nov 20 16:48 net_cls -> net_cls,net_prio
drwxr-xr-x 2 root root 0 Nov 20 16:48 net_cls,net_prio
lrwxrwxrwx 1 root root 16 Nov 20 16:48 net_prio -> net_cls,net_prio
drwxr-xr-x 2 root root 0 Nov 20 16:48 perf_event
drwxr-xr-x 6 root root 0 Nov 20 16:48 pids
drwxr-xr-x 2 root root 0 Nov 20 16:48 rdma
drwxr-xr-x 6 root root 0 Nov 20 16:48 systemd
drwxr-xr-x 6 root root 0 Nov 20 16:48 unified
In my LAB environment I assume this could be related to the old Buster Host, which still has cgroupv1. But it’s interesting that the same behaviour with the CPU limit shows up as on a Bullseye Host.