I am building a new cluster of 4 servers… and everything works great until shutdown server.
I have reinstall these an additional 4 times.
First, I lost one server, and then have remove node and reinstall it again.
Second, I lost 2 servers from cluster, I removed them and redid lxd init on servers
Third time, one unit lost the complete lxd install from snap., reinstalled
Fourth Time, now… lxc list hangs and sudo lxd --debug --group lxd
DBUG[01-15|12:21:01] Connecting to a local LXD over a Unix socket
DBUG[01-15|12:21:01] Sending request to LXD method=GET url=http://unix.socket/1.0 etag=
All machine says Global database unavailable
It look like machines are doing a clean shutdown. Luckily these are new machine and I can ust erase and do it again, but this going to be 5th time and have no idea what is happening.
Being playing around with these servers. They install perfectly, They work perfectly. BUT and it is big one. If I shut them all down, they don’t come back easily. I can turn off one, or two they are all ok to bring back one.
I even went as far as trying lxd shutdown first then regular shutdown.
I found that if I do systemctl restart snap.lxd.daemon, I can get cluster running eventually, it takes like 10 minutes for cluster to work again.
I can’t believe that this is correct on empty machines sitting on my bench.
Is it that the database is corrupt or too big?
It is brand new
LXD 3.20 will be available in the coming weeks as snap. Please try with that once out since it has a lot of improvements in this area.
Right now I am worried. After having had LXD in production for years now, it seems as unreliable as ever in regard to being at any level fault tolerant.
My new cluster that is set to replace present cluster, because I am moving to another Data Center
It can’t be shutdown properly several times before it loses it. Waiting for new version does not make senses unless you know of a particular issue that is causing this.
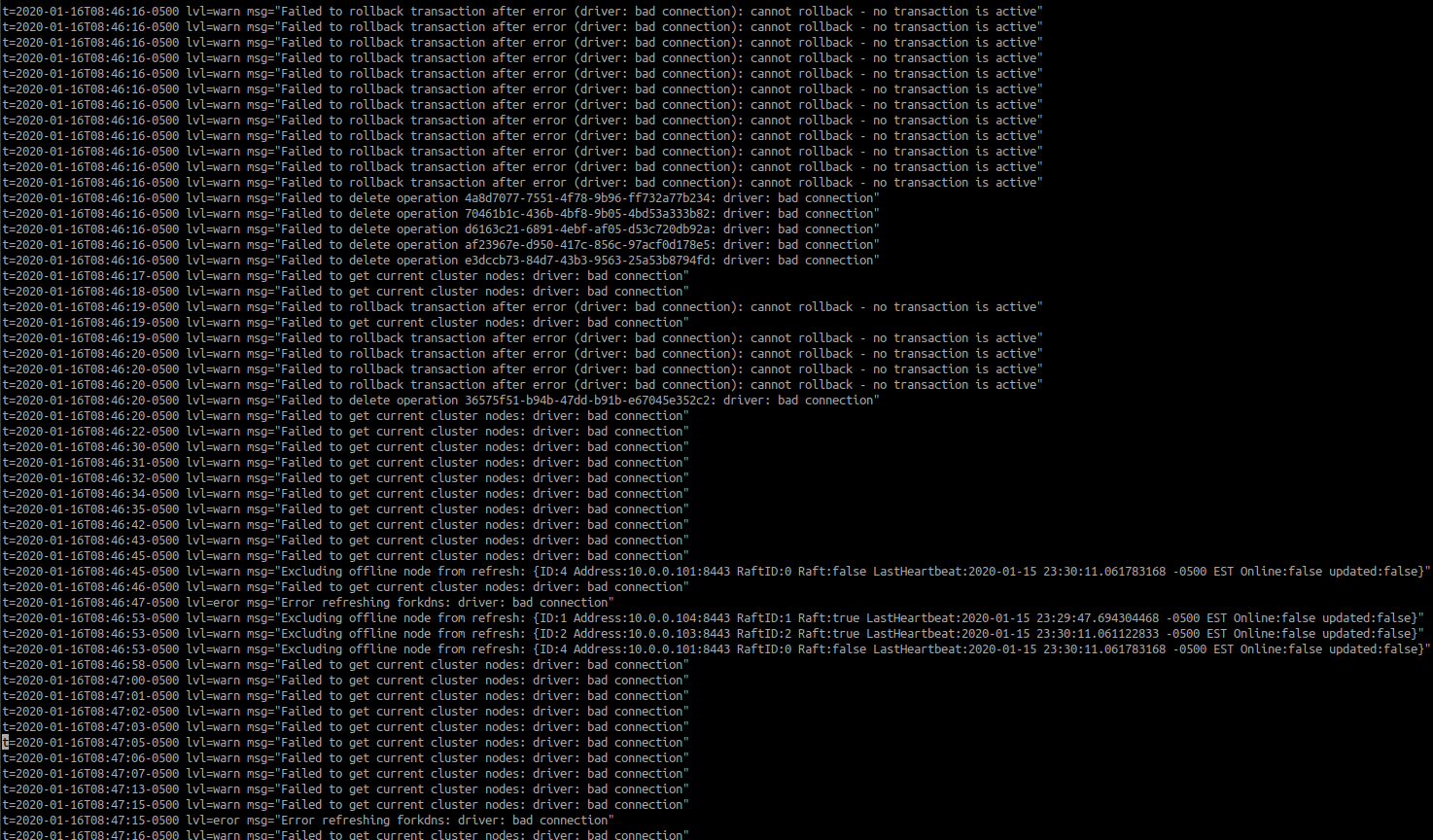
Take a look below, it looks like database is having communications issues.
lxc version
Client version: 3.18
Server version: unreachable
lxc list
Error: cannot fetch node config from database: driver: bad connection
lxd sql local ‘SELECT * FROM raft_nodes’
±—±----------------+
| id | address |
±—±----------------+
| 1 | 10.0.0.104:8443 |
| 2 | 10.0.0.103:8443 |
| 3 | 10.0.0.102:8443 |
±—±----------------+
lxd sql global ‘SELECT * FROM raft_nodes’
Error: Failed to execute query: driver: bad connection
see attached log picture.
I’m not aware of specific issues regarding shutting down members of a cluster. However 3.20 will have improvements that reduce API downtime in case you restart one or more cluster members: at the moment if you happen to restart the database leader, then API requests will hang or fail until a new leader is elected, which can take a few seconds. The new version should minimize such downtime.
Regarding your specific issue, do you have a detailed step-by-step procedure to reproduce it? We’re not observing it in our tests.
Unfortunately, nothing to replicate. It seems to happen eventually every time I shut down the cluster.
What makes this cluster different than others is that I am doing it as a test first at home. So after using it for a couple hours I turned it off every day, and then turn it on the next day. After I turn it on, it gives different errors but basically it does not stay stable.
IMHO, it should be able to go up and down (if shutdown properly) as many times as I want and should not die. There is no firewall install, and it is running via a local router.
But it seems to show bad connectivity to global database.
This is also very interesting
lxc version
Client version: 3.18
Server version: unreachable
Tomorrow, I am going to try again and reinstall the LXD.
I do the following to do a reinstall
snap remove lxd
snap remove lxc
sudo apt remove -y lxd
sudo apt autoremove
sudo zpool list
sudo apt purge lxd
dpkg --purge --force-all lxd
dpkg --reconfigure -a
sudo apt-get remove --purge snapd
sudo rm -rf /snap
sudo rm -rf /var/snap
rm -vf /etc/systemd/snap-.mount
rm -vf /etc/systemd/snap-.service
rm -vf /etc/systemd/snap-*.service
apt upgrade
Reboot
and then
apt install snap
apt install snapd
apt upgrade
reboot
snap install lxd
lxc
lxc version
lxd init
default everything
Everything works fine after this.
I do it to all 4 machines, It creates 3 database masters
I can bring down 1 or 2 units and it still functions.
But if I shutdown all computers, when they come up.
They are back to being paperweights.
Again, this should tell you something
lxc version
Client version: 3.18
Server version: unreachable
lxc list
Error: cannot fetch node config from database: driver: bad connection
lxd sql local ‘SELECT * FROM raft_nodes’
±—±----------------+
| id | address |
±—±----------------+
| 1 | 10.0.0.104:8443 |
| 2 | 10.0.0.103:8443 |
| 3 | 10.0.0.102:8443 |
±—±----------------+
lxd sql global ‘SELECT * FROM raft_nodes’
Error: Failed to execute query: driver: bad connection
Can I try 3.20 now. This is just a testing cluster now. And if it works then we now it is an 3.18 issue.
Thanks
tony
Ok, So I delete everything and reinstall all four servers. I used LXD 3.19 just for testing to see if it would do same thing.
I was able to bring down one of the database server and bring it up, no problem, but had to do a systemctl restart snap.lxd.daemon to make it become part of cluster again.
I was able to do the same with 2 and 3, both db servers, shutting them down, and starting ok. Had to restart service and eventually they would get back to working.
The fourth server, did the same thing, except this time when I would do restart, nothing would happen.
The Cluster is dead, all say same thing.
systemctl start lxd.socket
Failed to start lxd.socket: Unit lxd.socket not found.
This is the same problem that is all over the forum.
Seems to be communication issue of database .
root@QG3:/home/ic2000# lxd --debug --group lxd
INFO[01-17|22:52:27] LXD 3.19 is starting in normal mode path=/var/snap/lxd/common/lxd
INFO[01-17|22:52:27] Kernel uid/gid map:
INFO[01-17|22:52:27] - u 0 0 4294967295
INFO[01-17|22:52:27] - g 0 0 4294967295
INFO[01-17|22:52:27] Configured LXD uid/gid map:
INFO[01-17|22:52:27] - u 0 1000000 1000000000
INFO[01-17|22:52:27] - g 0 1000000 1000000000
INFO[01-17|22:52:27] Kernel features:
INFO[01-17|22:52:27] - netnsid-based network retrieval: no
INFO[01-17|22:52:27] - uevent injection: no
INFO[01-17|22:52:27] - seccomp listener: no
INFO[01-17|22:52:27] - seccomp listener continue syscalls: no
INFO[01-17|22:52:27] - unprivileged file capabilities: yes
INFO[01-17|22:52:27] - cgroup layout: hybrid
WARN[01-17|22:52:27] - Couldn’t find the CGroup memory swap accounting, swap limits will be ignored
INFO[01-17|22:52:27] - shiftfs support: no
INFO[01-17|22:52:27] Initializing local database
DBUG[01-17|22:52:27] Initializing database gateway
DBUG[01-17|22:52:27] Start database node id=3 address=10.0.0.103:8443
EROR[01-17|22:52:27] Failed to start the daemon: Failed to start dqlite server: raft_start(): io: load closed segment 0000000000001095-0000000000001153: entries batch 74 starting at byte 785000: entries count in preamble is zero
INFO[01-17|22:52:27] Starting shutdown sequence
DBUG[01-17|22:52:27] Not unmounting temporary filesystems (containers are still running)
Error: Failed to start dqlite server: raft_start(): io: load closed segment 0000000000001095-0000000000001153: entries batch 74 starting at byte 785000: entries count in preamble is zero
It dies here. These poor guys can see the other servers
DBUG[01-17|22:54:24] Dqlite: server connection failed err=failed to establish network connection: Head https://10.0.0.102:8443/internal/database: dial tcp 10.0.0.102:8443: connect: no route to host address=10.0.0.102:8443 id=1 attempt=0
DBUG[01-17|22:54:24] Dqlite: server connection failed err=failed to establish network connection: Head https://10.0.0.104:8443/internal/database: dial tcp 10.0.0.104:8443: connect: connection refused address=10.0.0.104:8443 id=1 attempt=0
DBUG[01-17|22:54:24] Dqlite: server connection failed err=failed to establish network connection: Head https://10.0.0.103:8443/internal/database: dial tcp 10.0.0.103:8443: connect: connection refused address=10.0.0.103:8443 id=1 attempt=0
At this point, I can reinstall all the servers and get it working again…but if I shut them down, same thing will happen. It loses the unix.socket thingy. There is obviously something very wrong here.
I could be something unique to my install, but it is just a fresh copy of ubuntu18.04 will all the upgrades before I install LXD on Supermicro servers. Nothing special not even a RAID.
Any help would be helpful since I have to move a large cluster, and I have spent 2 week already debugging what should have taken a day.
I spent another bunch of hours rebuilding and testing cluster today and I have narrowed down to more specifics.
The problem is related to individual machines losing there ability to communicate with each other over /var/snap/lxd/common/lxd/unix.socket. If it only one machine down, either database machine or not, I can get it working again pretty easily with systemctl restart snap.lxd.daemon.
However, if two or more are down, it can take along time and many times to get it working.
If I bring down all four, it takes 5-10 minutes of
systemctl restart systemd-networkd
systemctl restart snap.lxd.daemon.unix.socket
systemctl stop snap.lxd.daemon
systemctl restart snap.lxd.daemon
to make them work again.
There is catch 22 situation going on, the unix.socket is unavailable, and then cluster server are unavailable and then it gets stuck in a loop.
I can get it running but it is not very elegant to be hitting with a hammer. This seems to be a problem that has been around since early versions of LXD.
The whole cluster master, voting and retry system is pretty intolerant of any thing as simple as a reboot. I hope 3.20 is better, because this is the weakest part of LXD.
I hope my countless hours of playing with this thing help someone down the line.
I am going to chime in and say that I have also seen these quirky behaviors at least two separate times when I had to shutdown an entire 3 machine cluster for power outages.
Cluster is running the following snap version:
$ lxc version
Client version: 3.18
Server version: 3.18
After all of the machines were back up and running I encountered issues with ‘lxc list’ and ‘lxc cluster list’ commands. I have seen explicitly this error message too:
Error: Failed to execute query: driver: bad connection
I am not sure what ‘driver: bad connection’ means specifically. My best guess is some sort of stale or half closed connection that the code isn’t effectively detecting or re-opening. I doubt the error message is pointing at any other networking related issue because the same 3 machines are hosting a Ceph cluster that comes up without issue into a HEALTH_OK state.
Thinking about this aloud, what could lead to a bad connection? Does LXD have any sort of timeout or grace period during which all cluster nodes must return or it will fail? In other words, what would happen if say 1 out of 3 nodes didn’t come back online for 2-3 hours after the first two?
Hopefully I can help come across some more meaningful steps to reproduce the issue.
Regarding:
Error: Failed to execute query: driver: bad connection
that’s returned if one of the following errors happens 5 times in a row with a retry interval of 250 milliseconds:
- current leader loses leadership
- network connection to current leader is broken
The error is transient if a majority of cluster nodes is up, because they will eventually elect a new healthy leader (so ‘lxc list’ and ‘lxc cluster list’ will eventually stop returning that error).
If 1 out of 3 nodes doesn’t come back online fr 2-3 hours after the first two, the cluster will still be available, meaning that you can run ‘lxc list’ or ‘lxc cluster list’ on any of the two online nodes (or using any of them as remote). All other commands not requiring the offline node will work as well (e.g. you won’t be able to start a container on the offline node of course).
I definitely just caused the same issue with ‘snap stop lxd’ and ‘snap start lxd’ commands. I don’t have an exact sequence that caused it, but I am seeing a couple of alarming symptoms. The below happened with 1 of 3 machines always being kept “offline” by stopping the snap service.
First of all, the log on one node is getting flooded with:
lvl=warn msg=“Failed to get current cluster nodes: driver: bad connection”
Based on netstat output the lxd instance seems to be on a downward spiral of opening connections to itself:
$ sudo netstat -tnp | grep lxd | head -n25
tcp 0 0 10.0.5.190:8443 10.0.5.190:53054 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:57018 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:57156 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:55486 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:52732 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:56320 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:39202 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:35496 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:37820 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:53904 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:54498 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:36720 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:56488 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:56352 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:37160 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:38858 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:55988 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:54466 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:55898 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:54446 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:54736 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:55782 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.190:52748 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:56200 10.0.5.190:8443 ESTABLISHED 116157/lxd
tcp 0 0 10.0.5.190:8443 10.0.5.203:36370 ESTABLISHED 116157/lxd
Over time, the connection count keeps rising:
$ sudo netstat -tnp | grep lxd | wc -l
1623
$ sudo netstat -tnp | grep lxd | wc -l
1626
$ sudo netstat -tnp | grep lxd | wc -l
1628
$ sudo netstat -tnp | grep lxd | wc -l
1632
$ sudo netstat -tnp | grep lxd | wc -l
1711
On a second node the log was showing periodic:
lvl=warn msg=“Failed connecting to global database (attempt 55): failed to create dqlite connection: no available dqlite leader server found”
Likewise the machine seemed to be spiraling with connections:
$ sudo netstat -tnp | grep lxd | head -n25
tcp 0 0 10.0.5.203:53574 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:8443 10.0.5.203:54420 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54240 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:35860 10.0.5.190:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:35566 10.0.5.190:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:53758 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54402 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:53352 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:36402 10.0.5.190:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:34732 10.0.5.190:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:53250 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:8443 10.0.5.203:53930 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:53860 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:53458 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54790 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54036 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54668 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:35638 10.0.5.190:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:8443 10.0.5.203:53188 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:53448 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54002 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:8443 10.0.5.203:54888 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:8443 10.0.5.203:53232 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:54818 10.0.5.203:8443 ESTABLISHED 114464/lxd
tcp 0 0 10.0.5.203:35418 10.0.5.190:8443 ESTABLISHED 114464/lxd
$ sudo netstat -tnp | grep lxd | wc -l
806
$ sudo netstat -tnp | grep lxd | wc -l
938
$ sudo netstat -tnp | grep lxd | wc -l
1088
$ sudo netstat -tnp | grep lxd | wc -l
1729
The whole idea of having a 3 machines with one leader, that if that leaders dies, you have chaos is wrong. If you have 1 out of 3 go down, it should not be the end of the cluster. It computer should be it own master,and if it find someone else the one decides to be slave based on some priority table. Or it could even be last down. Right now it happens every single time I shut cluster down completely and start it.
I am going to look at open connections, I didn’t think of that. I was thinking it was just unix socket in general that was unavailable. Going to look at it tomorrow.
If you have 3 machines online, one of them at random will be elected as leader. If that leader dies, and you still have 2 machines online, another leader will be automatically elected at random. If the new leader in turns dies and you are left with only one machine, the cluster will be unavailable.
You can reboot the whole cluster and once a majority of machines come back online eventually a new leader will automatically be elected and the cluster will be available.
As mentioned, release 3.20 will bring some improvements that minimize the time the cluster is unavailable when the current leader gets shutdown gracefully, since that leader will transfer leadership to another online machine (if available) before shutting down, so no new election needs to take place.
Okay, it seems we have regressed in 3.19 wrt to 3.18.
I did several tests along the lines reported by @Tony_Anytime/@amcduffee and at least in one occasion I was able to deadlock the cluster.
The fix is in this PR:
Actually no, I was mistaken, sorry. The issue that the PR solves was introduced after 3.19, so it only affects master, not 3.19 or earlier. I’ll keep testing to see if I can reproduce what was reported.
A problem similar has been happening since version 3.xx something came about. It also happen in version 1, That is what I found in research. Not sure about before ver 3, But I can tell you for sure it happens in 3.18 and 3.19. Glad you are looking into it. I will look at code later to see if I can make sense of it. But the part that if leader dies and other is elected, voting dies if there is only one. And when you do a reboot, different machines boot at different times so you will always have one machine first, and then it looks like it locks up from there. I believe that is why I have to keep restarting lxd then until they sync up.
BTW, My little script to make it work
echo ‘Reseting Networking’
systemctl restart systemd-networkd
sleep 10
echo ‘Stopping Socket’
systemctl stop snap.lxd.daemon.unix.socket
sleep 10
echo ‘Starting Unix Socket’
systemctl start snap.lxd.daemon.unix.socket
sleep 10
echo ‘Stopping lxd’
systemctl stop snap.lxd.daemon
echo ‘Starting lxd’
systemctl restart snap.lxd.daemon
sleep 10
lxc cluster list
Ok, I might have found the issue, and I pushed a fix here:
https://github.com/lxc/lxd/pull/6746/commits/8a23715f5c1c63b9bdbdc32273d006ea2e1ca20f
it will be merge into master and included in 3.20.
Will see what @stgraber thinks about backporting it to 3.19.
Cool… thanks. … because you know, “Murphy always happens when you least expect it and not in the node you expect”
How long before 3.20 is coming?
Within 2 weeks I think.