My goal is to have a single, large, VM that is running openstack where I can run both VM’s and LXD containers simultaneously. There are better designs but my requirement is fixed, (1) vm, common dashboard for management, distributed images lxd & KVM via tarballs, support of VM’s & containers.
Proxmox gives me this to some extent but it is proprietary and the licensing is incompatible with the desired use and distribution of the environment.
So I have “successfully” deployed an Openstack environment in a vm using the openstack-on-lxd info as a guide. I have documented where I have deviated but the primary changes are as follows:
lxd init setup suing btrfs instead of zfs
(2) distinct compute nodes in lxd containers, (1) using virt-type=kvm & (1) using virt-type=lxd
(6) ceph-osd's using bluestore and changing all ceph-osd-replication-count=1 in all support charms
Since the default install and config of ceph using replication instead of erasure coding, can I reconfigure ceph, post juju, to use erasure coding for the backend storage?
After I configure the environment for erasure coding, if possible, the plan is to create availability zones and flavours so that I can spin up lxd instances on the lxd compute node and vm’s on the kvm compute node.
Looking for guidance on ceph first the multi-hypervisor config second.
@quartzeye Interesting reading about your setup. So, just seeking to understand how you’ve got this setup?
But first, to answer you question:
Since the default install and config of ceph using replication instead of erasure coding, can I reconfigure ceph, post juju, to use erasure coding for the backend storage?
Yes, you can, if it was deployed using Juju. And, if you are using the latest juju charms, the ~openstack-charmers ones from the charm store, you can do the changes using Juju actions: see the https://jujucharms.com/ceph-osd/ and https://jujucharms.com/ceph-mon/ for more details on the actions. Note that ceph-mon now has a ton of actions to do with creating pools, erasure profiles, etc., but they’re not yet documented in the README. Please take a look in the actions/ directory in the charm.
My goal is to have a single, large, VM that is running openstack where I can run both VM’s and LXD containers simultaneously. There are better designs but my requirement is fixed, (1) vm, common dashboard for management, distributed images lxd & KVM via tarballs, support of VM’s & containers.
So you have a host and then a single, large, libvirt VM. And in that you’ve deployed OpenStack using Juju in lxd containers? i.e. in the VM you bootstrapped the Juju controller into an LXD container, and then juju deployed a bundle to push the OpenStack control plane into LXD containers in the VM?
Inside that VM, you’ve configured two nova-compute Juju applications, one libvirt and one LXD, and thus you are also using the LXD charm?
So this means that, in the VM, you are using nested KVM (libvirt) and LXD?
So, how is the ceph configured? Are the OSDs external to the VM? How is the redundancy going to work with respect to where the OSDs are (Ceph defaults to splitting replicas by host, not disks)?
Alex,
Thanks for the response. I have been out of town and tied up with work but I am now back onto these issues.
Let’s start by dividing this into two parts.
First the erasure coding. I see the info in the actions but, as you said, they are undocumented. I am not sure where to start with this. Do I need to completely redeploy to get the erasure coding set up? Do I have to perform each action individually? In the JuJu admin console or at the command-line? I thought that JuJu would overwrite any config changes done at the command-line that differ from the admin console settings. The lack of a guide or working demo hampers my ability to figure this out as it is not exactly in my wheel house.
I did use the openstack-on-lxd as my base. I have a single VM. It has two virtual disks, (1) 500GB host system and (1) 2TB “openstack” disk. Host disk was formatted to xfs and the openstack disk was formatted to btrfs using “lxd init” processing.
Here are two pastebin links, the first is my entire build process to date, the second is the yaml file I used to deploy the openstack environment.
I also saw this the other day and have not yet figured out how to utilize this example:
What I did was build an 18.10 vm image and followed instructions on using kvm in a vm image. I believe that this is necessary in order to run kvm images inside a lxd container using kvm as a virt-type. I then installed the latest lxd from snap and ran the “lxd init” process. My build steps show the hoops I jumped through.
After all was running, I created host aggregates for each compute node and flavours then defined metadata so that the scheduler can properly send instances to the correct compute node for the appropriate virt-type. Again, this appears necessary to allow the scheduler to properly deploy an image with a flavour to the correct compute node.
The ceph config is in the yaml file. All the OSD’s are lxd containers running on the single 2TB openstack virtual drive. This is for simplicity as I did not want to complicate the config with a separate virtual drive for each OSD and allowed ceph to split the replicas by lxd container on the shared virtual drive.
Again, this is a demo environment using a virtual machine. All backup and resiliency is managed at the VM layer using snapshots where replication would be inappropriate due to the overuse of storage by the default 3X replicate factor. This is why erasure coding is needed. Erasure coding for 5:1 allows for an 83% utilization of the host storage vs 33% for replicates. Restoration can be accomplished by proper snapshot and vm management. It boggles my mind why erasure coding isn’t used by default as storage, no matter how cheap, adds up when you need 3X of it for everything. Hardware performance can be purchased much cheaper than replicating hardware to achieve the desired throughput. At least up to a point.
The last thing is getting the instances to run on their respective compute nodes. I have yet to get this far as I have not wanted to load up my VM with images until the erasure coding issue is resolved. However, does my config look correct? Are my assumptions correct? Someone recommended cells and I have not determined if that is more or less viable or easier to build and maintain than host aggregates.
With out a clear end-to-end guide, I have resorted to piecing together scarps from the internet to get this image working. Any help and guidance is appreciated.
@quartzeye
To be clear the blog post you’re referencing does not use the official openstack charms. When you deploy the openstack-on-lxd bundle you are using the official charms. Considering what you are trying to do, I think you’re doing the right thing using openstack-on-lxd.
The forks that I wrote and use are something like a year old and the official charms now have erasure support which is what you should be looking to use in my opinion. You want a full openstack and that’s what you get with the bundle you are currently using. To avoid confusion you shouldn’t be trying to use any of the erasure coding configurations you see on the linked blog with the current openstack implementation of erasure coding. I’m sure Alex can give you some pointers on reducing storage overhead in a demo single node openstack setup be that erasure or otherwise.
Having not done it myself though, I don’t believe you will need to redeploy. Ceph pool configuration is not something the charm will change out from under you. I’m willing to bet, just from an initial glance that you’ll run some actions to setup the pools you want and you’ll be good to go. I am curious if actions exist for osd level failure domains, although I suspect even if they aren’t there yet you could do it via ceph directly. While maybe not ideal it is still better for your use case than using forked charms since you do want the full openstack experience.
If I were to run full openstack I wouldn’t do it any other way than upstream stable charms from openstack-charmers.
Chris,
I fully intend to use the supported official charms. I included the link only as a reference to an approach as a discussion point. The official charms used in the openstack-on-lxd do not use the ceph-fs charm and I was not sure “if” it was needed for erasure coding. As I said in my note back to Alex, the lack of an example or guide, in addition to the minimalist documentation I have found so far, doesn’t provide me enough information to figure this all out. My hope is that Alex can guide me enough where I can get a working image running and allow me to put together a cursory guide for others to work with.
So I have taken a stab and getting erasure coding configured.
I was following along with the info in this link:
Doing the following commands with in the ceph-mon/0* container.
Create erasure code profile
ceph osd erasure-code-profile set ec-51-profile k=5 m=1 plugin=jerasure technique=reed_sol_van crush-failure-domain=host
Create erasure coded pool
ceph osd pool create ec51 64 erasure ec-51-profile
Enable overwrites
ceph osd pool set ec51 allow_ec_overwrites true
Tag EC pool as RBD pool
ceph osd pool application enable ec51 rbd
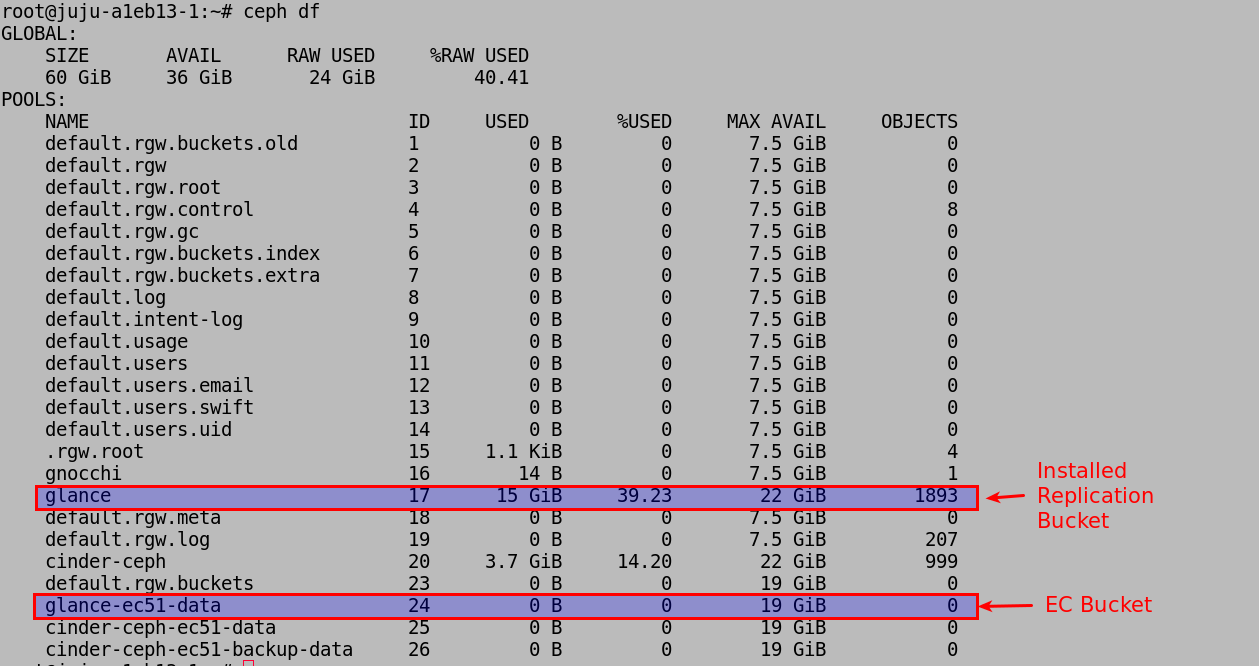
However, when I got to the section on “Using EC pools with RBD”, I realized that there were no RBD pools in the default install so I could not continue. I only see RGW pools.
It seems straight forward but I do have questions.
First, am I correct that I should be using RGW pools rather than RBD pools,
Second, it appears in the article that it is a “create, copy, rename” process rather than converting. Although I have no images or instances in my environment as yet. For recovery purposes, I will probably take that approach.
Third, what about the glance, gnocchi, and cinder-ceph default pools. Do I need to convert those to EC pools as well? I would think that I would as I “assume” that they are using replication.
Fourth, once I have converted the RGW pools to use EC. Do I need to change anything in the other service containers as I am eventually renaming the EC pools back to the default name at install?
Lastly, I am doing this all from inside the ceph-mon/0* container, is the a workable approach? I looked at the JUJU actions for the Ceph_Mon charm and was not sure how to accomplish all the necessary steps correctly.
From the PDF I at least understand the layout for the RGW buckets and can see that only the default.rgw.buckets pool needs to be converted. Also that the bucket holds the objects. I still am still not sure how block devices will be handled especially related to adding a secondary block device to an instance for increased storage or application requirements. Namely with Kubernetes as it needs a dedicated partition at install and generally this is provided by adding an unformated unmounted block device. My hope is that become objects in the rgw data bucket rather than a whole new set of rbd pools and buckets.
All the other buckets in the rgw space are service buckets and replication is expected for those.
However, it still doesn’t clear up the questions about the glance, gnoochi, and cinder-ceph pools. or the potential need for rbd pools. I did see in the ceph docs that radosgw will create the zone pools automatically when it is asked to operate on a pool that does not exist.
So that begs the question, When I start putting images into the system, creating block devices, etc., will the radosgw create those pools and buckets at that time, instead of at the initial install? If all the work effort going forward is not in the rgw pools will I have to actually exercise the system to have the pools created then convert the data pools to use EC? Again, if so, shouldn’t I be able to create these at install as well as define them as EC buckets?
I know it is a lot but the info just doesn’t seem to be out there in one place and I do not know what “assumptions” are made about the environment by the charms developers.
I plan to proceed ahead and convert the rgw data bucket then attempt to put an image in glance to see if it creates the other buckets, then convert that data bucket as well, if necessary. This might be a tedious process.
It looks like gnoochi isn’t going to be an issue and can be left as is. It is storing time series data and, I believe, only supports the OpenStack environment and not a DBaaS model for images.
Cinder-Ceph is storing the block devices and is an rbd pool. I am sure it is doing replication by default and I believe I can simply add an EC data pool, as I documented in my earlier response, then update the ceph.conf file to add in a stanza pointing to the default data pools. Something like the following:
[client.cinder]
rbd default data pool = cinder-ceph-ec51-data
[client.cinder-backups]
rbd default data pool = cinder-ceph-ec51-backup-data
I believe this will allow the metadata to flow into the default, replicated, rbd pool and the data/objects to flow into the default data pool, erasure coded.
Glance is also an rbd pool and if the above is true, I should be able to do the same for glance.
Sorry for this but another question comes to mind. All the examples I have seen show the ceph.config file being updated to reflect the default data pool. Should this instead be in the cinder.conf and glance.conf files in their respective containers?
So I’ve now had a chance to chat to some folks about this, and I think I can shed some additional light on what you are doing; however, you’re making great progress, so you’ve probably figured most of this out! So, if I apologise if this is pitched at too basic a level.
I think that this is orthogonal to the use of replication in pools and/or erasure coding in pools. A little recap:
A the bottom of the stack is RADOS, which has the OSDs, and they just store blocks.
Then you have the monitors (MONs) that monitor the OSD status, and the cluster map.
Then you have LIBRADOS which talks to the OSDs and MONs, and provides an API for things to access the blocks in the CEPH storage.
Finally, there are the ‘apps’, which are RADOSGW (storing objects), RDB (RADOS Block Device), and CephFS (file system semantics), which also uses a metadata store.
Then, in order to manage grouping of objects, you have:
The names of the pools RGW and RDB are just the conventional names for the pools for the RadosGW app and the RADOS Block Device App.
However, the Canonical distribution of OpenStack (CDO), glance and cinder (when using cinder-ceph), both store their images in default pool names for those applications (i.e. unless overriden the application name is the pool name), and Ceilometer and Gnochhi also use a pool named after the application name.
i.e. the default pools are not used as the charms configure a pool for each application service that is defined (cinder, glance, gnocchi, etc.)
Yes, we would agree with that approach.
Yes, basically. E.g. the cinder-ceph charm defaults the name of the ceph pool to the application name that the charm was deployed to (default is ‘cinder-ceph’), but for cinder-ceph, that can now be overridden with the ‘rdb-pool-name’ config value.
No, if the pool names remain the same afterwards, then everything should just work. The replication count and erasure coding are largely transparent to the charms (apart from when they are specified in the charms, but erasure coding is too new for that!)
Yes, that should be fine.
I have some other notes that we are currently writing up that will be included in the charm documentation. But in their raw form, the most interesting bits are:
Charms
This document covers features that are currently being worked on in development; make sure you are using charms from the openstack-charmers-next team.
RADOS Gateway bucket weighting
The weighting of the various pools in a deployment drives the number of placement groups (PG’s) created to support each pool. In the ceph-radosgw charm this is configured for the data bucket using:
Note the default of 20% - if the deployment is a pure ceph-radosgw deployment this value should be increased to the expected % use of storage. The device class also needs to be taken into account (but for erasure coding this needs to be specified post deployment via action execution).
Ceph automatic device classing
Newer versions of Ceph do automatic classing of OSD devices. Each OSD will be placed into ‘nvme’, ‘ssd’ or ‘hdd’ device classes. These can be used when creating erasure profiles or new CRUSH rules (see following sections).
The classes can be inspected using:
$ sudo ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-1 8.18729 root default
-5 2.72910 host node-laveran
2 nvme 0.90970 osd.2
5 ssd 0.90970 osd.5
etc.
Configuring erasure coding
The RADOS gateway makes use of a number of pools, but the only pool that should be converted to use erasure coding (EC) is the data pool:
default.rgw.buckets.data
All other pools should be replicated as they are by default.
The percent-data option should be set based on the type of deployment but if the RADOS gateway is the only target for the NVMe storage class, then 90% is appropriate (other RADOS gateway pools are tiny and use between 0.10% and 3% of storage)
Note that the create-erasure-profile action has a number of other options including adjustment of the K/M values which affect the computational overhead and underlying storage consumed per MB stored. Sane defaults are provided but they require a minimum of five hosts with block devices of the right class.
To avoid any creation/mutation of stored data during migration, shutdown all RADOS gateway instances:
juju run --application ceph-radosgw \
"sudo systemctl stop ceph-radosgw.target"
The existing buckets.data pool can then be copied and switched:
Thanks a million. These are the steps I have taken so far:
Determine the ceph-mon primary instance
Unit Workload Agent Machine Public address Ports Message
ceph-mon/0* active idle 1 10.178.225.26 Unit is ready and clustered
Machine State DNS Inst id Series AZ Message
4 started 10.178.225.166 juju-a1eb13-1 bionic Running
Open the instance at the command line
lxc exec juju-a1eb13-1 bash
Open the ceph.conf file
vi /etc/ceph/ceph.conf
Add the following to the ceph.conf and save
[global]
mon_max_pg_per_osd = 400 <--- Change setting
mon allow pool delete = true <--- Add setting
After saving the ceph.conf exit back to the host
exit
Reboot host
After system has restart and you are logged in, reopen the instance at the command line
lxc exec juju-a1eb13-1 bash
Create an erasure code profile
ceph osd erasure-code-profile set ec-51-profile k=5 m=1 plugin=jerasure technique=reed_sol_van crush-failure-domain=host
Create erasure coded pools
ceph osd pool create default.rgw.buckets.new 32 32 erasure ec-51-profile
ceph osd pool create glance-ec51-data 32 32 erasure ec-51-profile
ceph osd pool create cinder-ceph-ec51-data 32 32 erasure ec-51-profile
ceph osd pool create cinder-ceph-ec51-backup-data 32 32 erasure ec-51-profile
Enable overwrites on erasure coded pools
ceph osd pool set default.rgw.buckets.new allow_ec_overwrites true
ceph osd pool set glance-ec51-data allow_ec_overwrites true
ceph osd pool set cinder-ceph-ec51-data allow_ec_overwrites true
ceph osd pool set cinder-ceph-ec51-backup-data allow_ec_overwrites true
Tag erasure coded pools
ceph osd pool application enable default.rgw.buckets.new rgw
ceph osd pool application enable glance-ec51-data rbd <--important change
ceph osd pool application enable cinder-ceph-ec51-data rbd <--important change
ceph osd pool application enable cinder-ceph-ec51-backup-data rbd <--important change
Swap existing rgw pool out with new erasure coded pool
ceph osd pool rename default.rgw.buckets default.rgw.buckets.old
ceph osd pool rename default.rgw.buckets.new default.rgw.buckets
Open the ceph.conf file
vi /etc/ceph/ceph.conf
Add the following to the ceph.conf and save
[client.cinder]
rbd default data pool = cinder-ceph-ec51-data
[client.cinder-backups]
rbd default data pool = cinder-ceph-ec51-backup-data
[client.glance]
rbd default data pool = glance-ec51-data
After saving the ceph.conf exit back to the host
exit
Reweight the rgw pools so that ceph expects 50% of the data to be in the rgw pool
juju config ceph-radosgw rgw-buckets-pool-weight=50
I was not sure about shutting down ceph will the system was running so I just rebooted after a config change.
The info you provided was very relevant. Just to be certain though:
Glance stores the base image in its “glance” pool, i.e. the .raw files I might download for the base OS or any re-distributable custom image where I have deployed middle-ware. I have created a separate EC data pool and config’d the default data pool to the new EC data pool.
Cinder stores block devices in its “cinder-ceph” pool, i.e the persistent volumes I might add to base image from glance for storing data between instances of running images. I have created a separate EC data pool and config’d the default data pool to the new EC data pool.
This is where I am a bit fuzzy. The default.rgw.buckets is where everything sits while running. Upon snaphoting or instance shutdown, data is written back to glance, snapshot, or cinder, snaphot or volume updates.
So I am not sure why setting rgw-buckets-pool-weight=90 in my environment would work. I certainly see that in a real world situation, you could have many instances of a image running. In my case I have practically a one-to-one relationship between images and instances. Rarely will I have multiple instances of the same image. I have only two cases where that might occur, creating a three node kubernetes cluster instance, and creating a three node hadoop cluster instance where the worker nodes of each cluster might be built off of the same image. In my case I can see where setting the percentage to approximately 50%, to start with, and adjusting it after exercising the system to tune it may be more appropriate.
I welcome your thoughts and input. I will be importing images today so I should get an idea if my storage scheme is working very soon.
So it looks like my ceph build steps are not working. I uploaded a number of images and when I look at ceph I do not see the data going into the EC bucket I created. I set the replication level to 1 in the original install so I do see that I only have 1 stored image for each that I imported.
So do I simply delete the original bucket and replace it with the EC bucket I created? What about the metadata, my understanding is that needs to remain in a replicated bucket.
Also. I moved ahead and tried to test the environment. I cannot get an LXD instance started. I followed the steps in the openstack-on-lxd site and imported images and created flavours.
I downloaded these images but from the instructions the image to download fails to start on the LXD compute node.
The download site doesn’t really help me determine which is an LXD image and which is a KVM image. The openstack-on-lxd site infers that the image I downloaded, xenial-server-cloudimg-amd64-disk1.img, is an LXD image but the openstack docs infer it is a KVM image.
Which is it? It’s qcow2 formatted so I assume it is KVM. How do I know if an image is KVM or LXD? Does it matter? This is even more problematic with CentOS images. I followed the Openstack doc link and downloaded the latest CentOS 7 image, again assuming it was a KVM image. I still have not found where I can down load a CentOS LXD image that I can import into Openstack and I cannot export it from my host LXD system as I cannot get a single unified tarball to export, I only get the the squashfs and metadata files that I can not seem to import into Openstack.
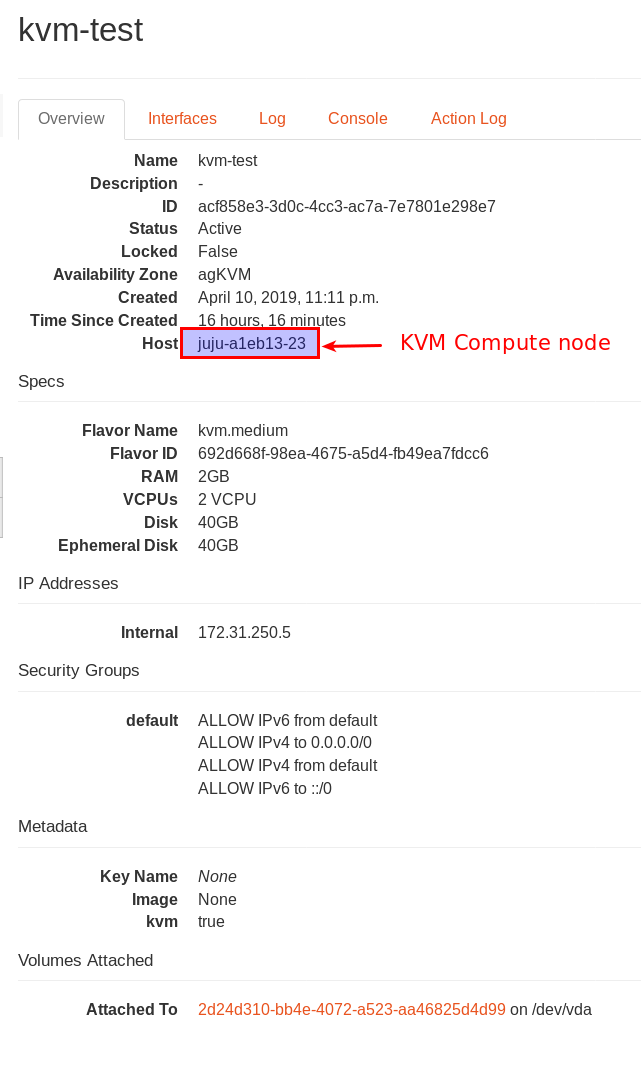
I then spun up a test instance that you can see running in my error image above. If I look at the info on the instance, I can see that it running on the KVM compute node.
So I need to finish up the erasure code config and figure out why the data is not going into the EC bucket.
I then need to resolve the following
Where do I download KVM images for Openstack
Where do I download LXD images for Openstack
Why does it appear the a KVM image is running as a LXD instance on a KVM compute node
Why will an assumed LXD image will not start on a LXD compute node.
Alex,
I have success. I copied the ceph.conf changes to the other (2) ceph_mon containers and also to the glance and cinder instances. I now see images being stored in my EC pool and the omap data going into the installed service replicated pool.
However, I still cannot get a LXD container started on the LXD compute node. I also think that the KVM images are starting on the KVM compute node properly.
So now I am waiting for someone with more knowledge than me to look at my last post and see if they can reply with something to try of a fix.
Thanks again for all the help so far. I feel I am very close to a working environment and hope someone can see what I am missing.
So I pulled the section of the log related to my effort to spin up an image on the lxd compute node. The log is below but I think that openstack is unable to find the image I want to launch. Even though it is in the GUI and uploaded to glance. I suspect that the image might not be a lxd image. It also may be uploaded and the wrong image format was selected, I used “raw”. I am uncertain at this point on how to proceed.
2019-04-11 15:15:40.240 642 INFO nova.compute.resource_tracker [req-bcf2b1d2-4f71-45ae-82ab-2c2cdfcdada9 - - - - -] Final resource view: name=juju-a1eb13-24 phys_ram=52328MB used_ram=512MB phys_disk=1999GB used_disk=0GB total_vcpus=8 used_vcpus=0 pci_stats=[]
2019-04-11 15:15:45.058 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Attempting claim on node juju-a1eb13-24: memory 2048 MB, disk 80 GB, vcpus 2 CPU
2019-04-11 15:15:45.058 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Total memory: 52328 MB, used: 512.00 MB
2019-04-11 15:15:45.059 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] memory limit: 3348992.00 MB, free: 3348480.00 MB
2019-04-11 15:15:45.059 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Total disk: 1999 GB, used: 0.00 GB
2019-04-11 15:15:45.059 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] disk limit not specified, defaulting to unlimited
2019-04-11 15:15:45.059 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Total vcpu: 8 VCPU, used: 0.00 VCPU
2019-04-11 15:15:45.060 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] vcpu limit: 512.00 VCPU, free: 512.00 VCPU
2019-04-11 15:15:45.060 642 INFO nova.compute.claims [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Claim successful on node juju-a1eb13-24
2019-04-11 15:15:45.478 642 INFO nova.virt.block_device [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Booting with blank volume at /dev/vda
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Instance failed to spawn: nova.exception.ImageNotFound: Image could not be found.
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Traceback (most recent call last):
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/virt/lxd/driver.py”, line 525, in spawn
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] self.client.images.get_by_alias(instance.image_ref)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/pylxd/models/image.py”, line 83, in get_by_alias
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] response = client.api.images.aliases[alias].get()
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/pylxd/client.py”, line 125, in get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] self._assert_response(response, stream=kwargs.get(‘stream’, False))
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/pylxd/client.py”, line 90, in _assert_response
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] raise exceptions.NotFound(response)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] pylxd.exceptions.NotFound: not found
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460]
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] During handling of the above exception, another exception occurred:
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460]
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Traceback (most recent call last):
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/glance.py”, line 242, in show
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] image = self._client.call(context, 2, ‘get’, image_id)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/glance.py”, line 179, in call
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] result = getattr(controller, method)(*args, **kwargs)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/v2/images.py”, line 197, in get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return self._get(image_id)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/common/utils.py”, line 545, in inner
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return RequestIdProxy(wrapped(*args, **kwargs))
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/v2/images.py”, line 190, in _get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] resp, body = self.http_client.get(url, headers=header)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/keystoneauth1/adapter.py”, line 328, in get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return self.request(url, ‘GET’, **kwargs)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/common/http.py”, line 349, in request
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return self._handle_response(resp)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/common/http.py”, line 98, in _handle_response
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] raise exc.from_response(resp, resp.content)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] glanceclient.exc.HTTPNotFound: 404 Not Found: The resource could not be found. (HTTP 404)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460]
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] During handling of the above exception, another exception occurred:
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460]
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Traceback (most recent call last):
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/compute/manager.py”, line 2357, in _build_resources
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] yield resources
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/compute/manager.py”, line 2121, in _build_and_run_instance
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] block_device_info=block_device_info)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/virt/lxd/driver.py”, line 530, in spawn
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] self.client, context, instance.image_ref)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/virt/lxd/driver.py”, line 280, in _sync_glance_image_to_lxd
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] image = IMAGE_API.get(context, image_ref)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/api.py”, line 105, in get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] show_deleted=show_deleted)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/glance.py”, line 244, in show
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] _reraise_translated_image_exception(image_id)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/glance.py”, line 893, in _reraise_translated_image_exception
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] six.reraise(type(new_exc), new_exc, exc_trace)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/six.py”, line 692, in reraise
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] raise value.with_traceback(tb)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/glance.py”, line 242, in show
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] image = self._client.call(context, 2, ‘get’, image_id)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/nova/image/glance.py”, line 179, in call
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] result = getattr(controller, method)(*args, **kwargs)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/v2/images.py”, line 197, in get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return self._get(image_id)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/common/utils.py”, line 545, in inner
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return RequestIdProxy(wrapped(*args, **kwargs))
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/v2/images.py”, line 190, in _get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] resp, body = self.http_client.get(url, headers=header)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/keystoneauth1/adapter.py”, line 328, in get
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return self.request(url, ‘GET’, **kwargs)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/common/http.py”, line 349, in request
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] return self._handle_response(resp)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] File “/usr/lib/python3/dist-packages/glanceclient/common/http.py”, line 98, in _handle_response
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] raise exc.from_response(resp, resp.content)
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] nova.exception.ImageNotFound: Image could not be found.
2019-04-11 15:16:08.669 642 ERROR nova.compute.manager [instance: 8754163e-b9a6-4a58-9ece-6c219613c460]
2019-04-11 15:16:08.671 642 INFO nova.compute.manager [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Terminating instance
2019-04-11 15:16:08.680 642 WARNING nova.virt.lxd.driver [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] Failed to delete instance. Container does not exist for instance-00000004.: pylxd.exceptions.NotFound: not found
2019-04-11 15:16:08.690 642 INFO os_vif [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] Successfully unplugged vif VIFBridge(active=False,address=fa:16:3e:d1:0c:61,bridge_name=‘qbre9c4aaf6-d1’,has_traffic_filtering=True,id=e9c4aaf6-d164-4e82-9049-bf732791f9c5,network=Network(6acd1b06-ef55-4ee2-bbcb-deb98a9b1091),plugin=‘ovs’,port_profile=VIFPortProfileOpenVSwitch,preserve_on_delete=False,vif_name=‘tape9c4aaf6-d1’)
2019-04-11 15:16:14.022 642 WARNING nova.virt.lxd.driver [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] Failed to delete instance. Profile does not exist for instance-00000004.: pylxd.exceptions.NotFound: not found
2019-04-11 15:16:14.024 642 INFO nova.compute.manager [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Took 5.35 seconds to destroy the instance on the hypervisor.
2019-04-11 15:16:14.454 642 INFO nova.compute.manager [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Took 0.43 seconds to detach 1 volumes for instance.
2019-04-11 15:16:16.393 642 INFO nova.compute.manager [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] [instance: 8754163e-b9a6-4a58-9ece-6c219613c460] Took 1.51 seconds to deallocate network for instance.
2019-04-11 15:16:16.678 642 INFO nova.scheduler.client.report [req-36b775e5-6da0-4b84-a05b-5bfaeb53fff3 b469aff11d2341bebcf9b4c5ccad4cea e8f369f06f1143c6a5855f632992286f - 98cc205a6dc94336a198a4abd4606653 98cc205a6dc94336a198a4abd4606653] Deleted allocation for instance 8754163e-b9a6-4a58-9ece-6c219613c460
2019-04-11 15:16:41.241 642 INFO nova.compute.resource_tracker [req-bcf2b1d2-4f71-45ae-82ab-2c2cdfcdada9 - - - - -] Final resource view: name=juju-a1eb13-24 phys_ram=52328MB used_ram=512MB phys_disk=1999GB used_disk=0GB total_vcpus=8 used_vcpus=0 pci_stats=[]
Here is the image info. It is “bare” and “raw”. lxd=true is metadata I added to everything LXD, the host aggregate, the flavour, the image, and the instance. No joy, the image will not start.
lxd=true is metadata I added to everything LXD
Please read what I said:
You should also set the property hypervisor_type=lxd on the image and on the flavour that you are trying to use for LXD
Its hypervisor_type=lxd, not lxd=true
Thanks for the advice but that did not work. I don’t think the issue is in the metadata, as yet. The error out of glance is that the image cannot be found. So when it tries to spawn the image it is asking glance for it and glance appears to be say it cannot find it. I googled it and found one or two other posts that referred to this error specifically when using LXD but no resolution of work arounds that I saw.