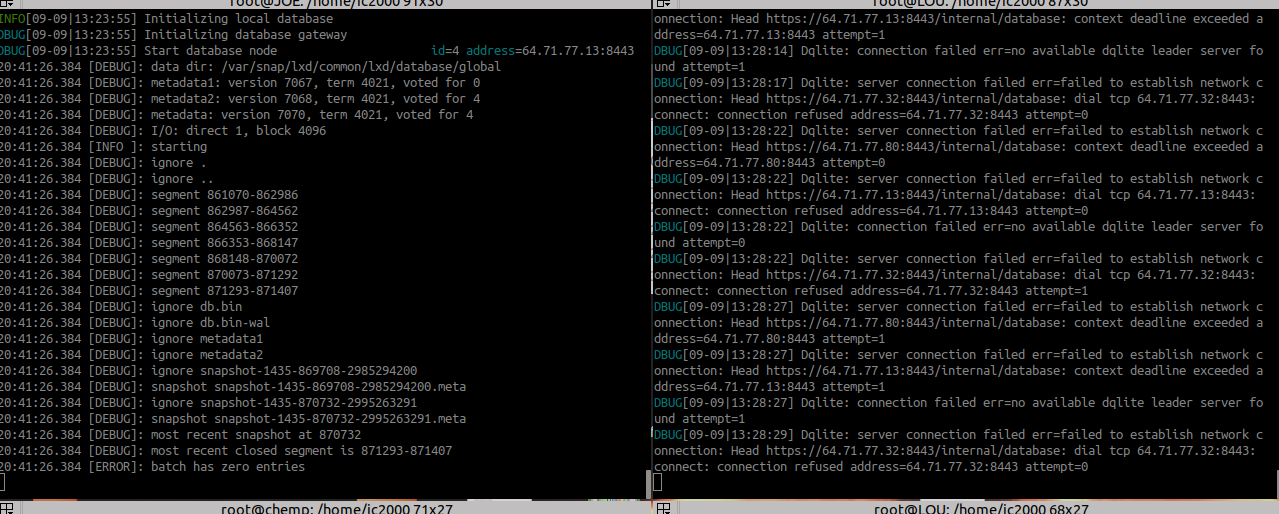
I started upgrading my servers from 3.16 to 3.17 and I am getting this error in cluster.
So wondering what is the best way to proceed, upgrade all and reboot, or is there something else wrong. I don’t want all my machines to become useless again and start a chain of reinstalling LXD on all my servers again. Presently Larry(LOU) , CHEMP and CURLYJOE on 3.17, have a problem, and JOE, MOE which are on 3.16 seem fine. Thanks in advance for your wisdom.
| CHEMP | https://64.xxx.18:8443 | NO | ONLINE | fully operational |
±---------±-------------------------±---------±--------±-----------------------------------+
| CURLYJOE | https://64.xxx.29:8443 | NO | ONLINE | fully operational |
±---------±-------------------------±---------±--------±-----------------------------------+
| JOE | https://64.xxx.13:8443 | YES | ONLINE | fully operational |
±---------±-------------------------±---------±--------±-----------------------------------+
| LARRY | https://64.xxx.80:8443 | YES | OFFLINE | no heartbeat since 1m11.774807161s |
±---------±-------------------------±---------±--------±-----------------------------------+
| MOE | https://64.xxx.32:8443 | YES | ONLINE | fully operational
systemctl stop lxd.service lxd.socket
Failed to stop lxd.service: Unit lxd.service not loaded.
Failed to stop lxd.socket: Unit lxd.socket not loaded.
root@LOU:/home/ic2000# lxd --debug --group lxd
DBUG[09-09|09:56:42] Connecting to a local LXD over a Unix socket
DBUG[09-09|09:56:42] Sending request to LXD method=GET url=http://unix.socket/1.0 etag=
INFO[09-09|09:56:48] LXD 3.17 is starting in normal mode path=/var/snap/lxd/common/lxd
INFO[09-09|09:56:48] Kernel uid/gid map:
INFO[09-09|09:56:48] - u 0 0 4294967295
INFO[09-09|09:56:48] - g 0 0 4294967295
INFO[09-09|09:56:48] Configured LXD uid/gid map:
INFO[09-09|09:56:48] - u 0 1000000 1000000000
INFO[09-09|09:56:48] - g 0 1000000 1000000000
WARN[09-09|09:56:48] CGroup memory swap accounting is disabled, swap limits will be ignored.
INFO[09-09|09:56:48] Kernel features:
INFO[09-09|09:56:48] - netnsid-based network retrieval: no
INFO[09-09|09:56:48] - uevent injection: no
INFO[09-09|09:56:48] - seccomp listener: no
INFO[09-09|09:56:48] - unprivileged file capabilities: yes
INFO[09-09|09:56:48] - shiftfs support: no
INFO[09-09|09:56:48] Initializing local database
DBUG[09-09|09:56:48] Initializing database gateway
DBUG[09-09|09:56:48] Start database node id=2 address=64.71.77.80:8443
DBUG[09-09|09:56:48] Connecting to a local LXD over a Unix socket
DBUG[09-09|09:56:48] Sending request to LXD method=GET url=http://unix.socket/1.0 etag=
DBUG[09-09|09:57:00] Detected stale unix socket, deleting
DBUG[09-09|09:57:00] Detected stale unix socket, deleting
INFO[09-09|09:57:00] Starting /dev/lxd handler:
INFO[09-09|09:57:00] - binding devlxd socket socket=/var/snap/lxd/common/lxd/devlxd/sock
INFO[09-09|09:57:00] REST API daemon:
INFO[09-09|09:57:00] - binding Unix socket socket=/var/snap/lxd/common/lxd/unix.socket
INFO[09-09|09:57:00] - binding TCP socket socket=64.7xx.80:8443
INFO[09-09|09:57:00] Initializing global database
DBUG[09-09|09:57:01] Found cert name=0
WARN[09-09|09:57:05] Dqlite client proxy TLS -> Unix: read tcp 64.xx.80:51906->64.xx.32:8443: use of closed network connection
DBUG[09-09|09:57:05] Dqlite: server connection failed err=failed to establish network connection: Head https://64.xx.32:8443/internal/database: context deadline exceeded address=64.xxx.32:8443 attempt=0
DBUG[09-09|09:57:05] Found cert name=0
DBUG[09-09|09:57:05] Dqlite: server connection failed err=failed to establish network connection: 503 Service Unavailable address=64.xxx.80:8443 attempt=0
DBUG[09-09|09:57:05] Dqlite: server connection failed err=failed to establish network connection: 503 Service Unavailable address=64.xx.13:8443 attempt=0
DBUG[09-09|09:57:05] Dqlite: connection failed err=no available dqlite leader server found attempt=0
DBUG[09-09|09:57:06] Found cert name=0
DBUG[09-09|09:57:06] Found cert name=0
DBUG[09-09|09:57:07] Found cert name=0
DBUG[09-09|09:57:07] Found cert name=0
DBUG[09-09|09:57:07] Found cert name=0
DBUG[09-09|09:57:07] Found cert name=0
DBUG[09-09|09:57:08] Found cert name=0
DBUG[09-09|09:57:09] Found cert name=0
DBUG[09-09|09:57:10] Found cert name=0
WARN[09-09|09:57:10] Dqlite client proxy TLS -> Unix: read tcp 64.xx.80:51920->64.xxx.32:8443: use of closed network connection
DBUG[09-09|09:57:10] Dqlite: server connection failed err=failed to establish network connection: Head https://64.xx.32:8443/internal/database: context deadline exceeded address=64.xxx.32:8443 attempt=1
DBUG[09-09|09:57:10] Dqlite: server connection failed err=failed to establish network connection: Head https://64.71.77.80:8443/internal/database: context deadline exceeded address=64.xx.80:8443 attempt=1
DBUG[09-09|09:57:10] Dqlite: server connection failed err=failed to establish network connection: Head https://64.xxx.13:8443/internal/database: context deadline exceeded address=64.xxxx.13:8443 attempt=1
DBUG[09-09|09:57:10] Dqlite: connection failed err=no available dqlite leader server found attempt=1
DBUG[09-09|09:57:10] Failed connecting to global database (attempt 0): failed to create dqlite connection: no available dqlite leader server found
DBUG[09-09|09:57:11] Found cert name=0
DBUG[09-09|09:57:11] Replace current raft nodes with [{ID:1 Address:64.xx.32:8443} {ID:2 Address:64.xx.80:8443} {ID:4 Address:64.xxx.13:8443}]
DBUG[09-09|09:57:11] Partial node list heartbeat received, skipping full update
DBUG[09-09|09:57:11] Found cert name=0
DBUG[09-09|09:57:11] Replace current raft nodes with [{ID:1 Address:64.xxx.32:8443} {ID:2 Address:64.xx.80:8443} {ID:4 Address:64.xxx.13:8443}]
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x20 pc=0x926824]
goroutine 243 [running]:
sync.(*RWMutex).RLock(…)
/snap/go/4301/src/sync/rwmutex.go:48
github.com/lxc/lxd/lxd/db.(*Cluster).Transaction(0x0, 0xc000719dc0, 0x0, 0x0)
/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/db/db.go:330 +0x34
github.com/lxc/lxd/lxd/cluster.MaybeUpdate(0xc000719e48, 0x0, 0x0)
/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/cluster/upgrade.go:68 +0x95
main.(*Daemon).NodeRefreshTask(0xc0001eed80, 0xc00022ec80)
/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/daemon.go:1339 +0x4d0
created by github.com/lxc/lxd/lxd/cluster.(*Gateway).HandlerFuncs.func1
/build/lxd/parts/lxd/go/src/github.com/lxc/lxd/lxd/cluster/gateway.go:218 +0xe49