I noticed that when we run a task that uses a lot of I/O inside an LXD container with I/O limitation, the host CPU load goes to an abnormal level, affecting another containers on the same host.
Example:
Setting I/O limit on container test:
lxc config device set test root limits.max 200B
Host load average: 0,25, 0,43, 0,49
If I run some I/O intensive command inside guest, like:
dd if=/dev/zero of=/root/testfile bs=1G count=1 oflag=dsync
Host load average: 11,28, 5,51, 2,46
In other words, if I limit guest I/O, the limitation also slow down other containers. When I am running the “dd” command with the limitation, I cannot even stop the container with the “–force” option (returns an SQLite error), I have to wait the “dd” command ends to operate LXD again.
I am using LXD 3.5 (snap rev 9010) and ZFS as storage backend. Someone has any idea how we can solve this problem? This can be dangerous because running one command inside the guest can affect the entire host.
Yes, I tried with some different values (10MB, 200B and others). I know that 200B is too little, but I used this value to test what happens with the host when the guest gets stuck in the I/O process.
The load is merely the number of processes waiting to be scheduled.
Your I/O limit will effectively make any process in this container stuck on I/O adding to that load value.
You can perfectly have a container with 1000 processes waiting for I/O or CPU, causing a system load of 1000, yet have every other container be perfectly responsive as they’re not affected by the scheduler constraint.
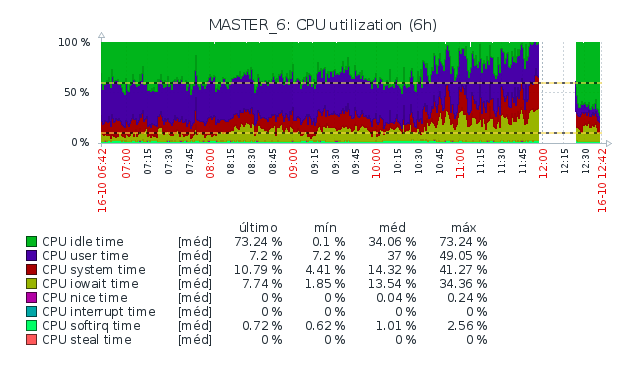
File attached is the CPU usage graph of the host machine when 1 limited container started do to an I/O intensive task. As you can see, the Zabbix Agent running on the host stopped responding too. Even SSH stopped working, the only way I encountered to access the host machine again was forcing physical reboot.
If you can, please test this scenario in you PC. Start one container, configure the I/O limit as 200B and run the “dd” command. You will see that other processes on the host like Chrome browser will become stuck until the “dd” process ends.
I did try it here and I’m not seeing that behavior at all.
What I’m seeing is one process stuck in D state as expected, it’s taking forever for it to read the dd binary from disk since it’s limited at 200B/s from block (so likely just a few B/s from fs).
No impact to my other running processes, my desktop works just fine, chrome is reponsive and overall system load moved up from 1.00 to 2.01.
It a very strange problem… I tested with two different machines and I also tested with the recent new version (3.6 rev 9206 snap) and the same problem occurred. I will keep testing and see if I encounter some logic, then I post here. If someone see this same behavior, please let me know!
In general ZFS has always played very weirdly with blkio limits, due to it being a filesystem port from Solaris based on the SPL driver.
It used to be that those limits had no impact at all on ZFS (as in, you’d get full performance regardless), looks like they’ve made some improvements there but it may vary greatly based on kernel releases.