I removed my host from the cluster to do maintenance and now I can’t get it back on. The problem doesn’t seem to be the trust password as when I paste something random I get the following in the logs.
What you mean with “removed my host from the cluster”?
To do maintenance of a LXD node in a cluster you can just shut it down, no need to remove it. You should remove it only when you don’t want it to belong to the cluster anymore.
In that case you need to join the node again as a brand new node. If you get a password error, I’d suggest to change your cluster password (to be really sure you are not entering the wrong password because perhaps you forgot it), then remove and reinstall the snap from the node to ensure you start from a fresh state, and then join the node again with lxd init.
That’s what I’ve done though. I manged to connect once and then had to downgrade to 4.0.3 because of incompatibility problems. Now when I try I get connection refused as per my initial post.
When I use the incorrect password it’s quite explicit.
That’s normal, you’ll normally only ever see 3 database servers no matter the number of servers. Which one is a database server may change over time as the role is transferred during restarts.
Unfortunately, now I can’t do anything with that container6 node.
lxc mv cluster-new:kibana-logging cluster-new: --target=container6
Error: Migration API failure: Failed to get address of instance's node: No such object
Very weird… Maybe do another round of systemctl reload snap.lxd.daemon on the various nodes? I’m not sure why that would help though, we send heartbeats every 10s or so and your output above shows that those have been sent an received properly so I’m not sure why you’d have cluster nodes that are unaware of others.
I tried that, and restarted the container6 box. It can’t see anything at all, despite no naming issues. I went in and added all the hosts to each others host files just in-case. This is what lxc list looks like on container6.
The time was WAAAAY off. I fixed that. I can now launch, just still can’t mv containers but that is now a general problem with the cluster, not associated with that node. #winning
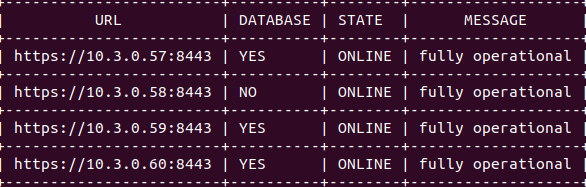
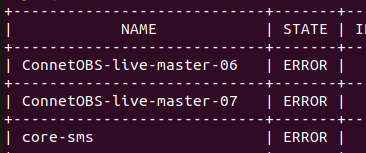
 Thanks for all the help with this. It looks like it’s sorted.
Thanks for all the help with this. It looks like it’s sorted.