With docker, you just put a couple lines of config with a subnet within your VPS’s subnet and it just works, PERFECTLY. Each container is given an IPv6, and it works for both inbound and outbound connections to the container.
Why can’t LXD be like this? It would be awesome to be able to spin up a container and immediately SSH directly to it with its IPv6 address without messing with inconvenient iptables port forwarding or those silly userspace LXD proxies that waste ram and mask the client IP addresses.
The only working solution I’ve found is this: Routing public IPv6 addresses to your lxc/lxd containers – TechOverflow, which is quite awful. I’ve tried configuring LXD with a public IPv6 subnet like I did with docker, but it does not work. I couldn’t find anything else helpful by googling.
This will work with routed IPv6? It did not work on non-routed block… I guess docker daemon sets up NDP proxying for it to work out of the box like that?
Ah yeah, we indeed don’t do NDP proxying , the config above expects that subnet to be routed to the host. So you’d need to separately turn on NDP proxying on the system.
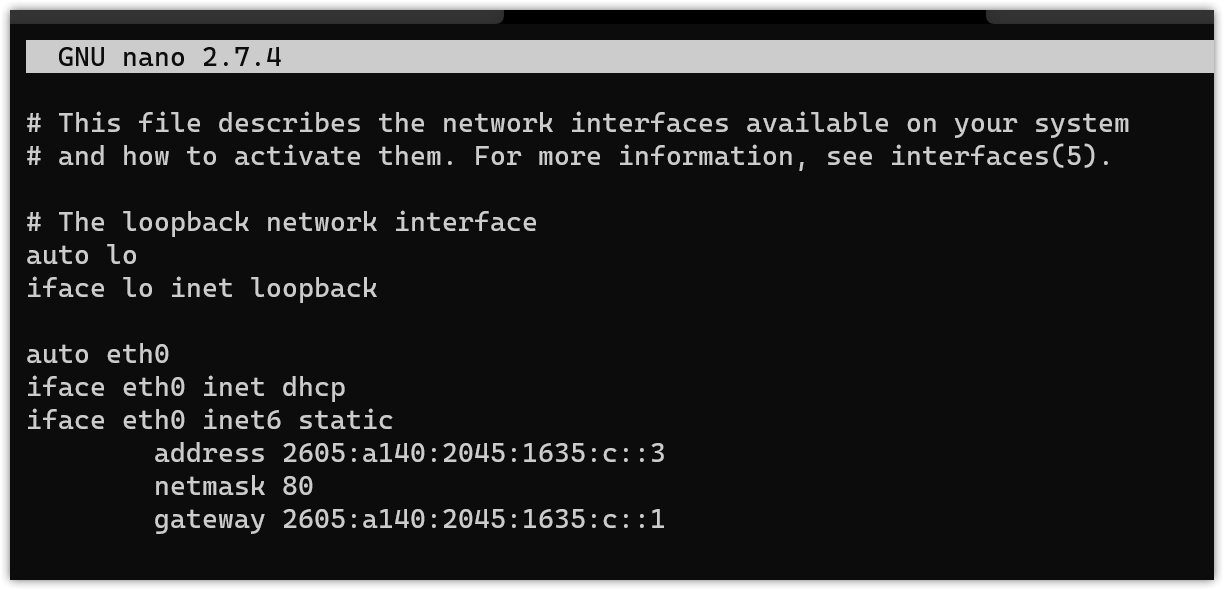
Well, before setting up NDP proxying, shouldn’t the containers be getting IPv6 addresses? My VPS’s IPv6 block is 2605:a140:2045:1635::1/64 and I set LXD’s ipv6.address to a subnet within it, 2605:a140:2045:1635:c::1/80.
Well, I discovered the lxd warning thing, and found this…
+--------------------------------------+---------------------------------------------------------------------------------+--------+---------+-------+---------+-------------------------------+
| 534100ac-db23-4de2-9848-93d4d6b0a96c | IPv6 networks with a prefix larger than 64 aren't properly supported by dnsmasq | NEW | LOW | 1 | default | Jul 16, 2021 at 10:38pm (UTC) |
+--------------------------------------+---------------------------------------------------------------------------------+--------+---------+-------+---------+-------------------------------+
So I cannot use an 80-bit prefix with LXD?
Surely I can’t give LXD my VPS’s one and only /64. Or can I? No, pretty sure I can’t, as eth0 interface already has it.
Hmm
Linux Containers - LXD - Has been moved to Canonical
Smaller subnets while in theory possible when using stateful DHCPv6 for IPv6 allocation aren’t properly supported by dnsmasq and may be the source of issue. If you must use one of those, static allocation or another standalone RA daemon be used.
So I’m really not sure whether my /64 block is routed or not. I did not set up any NDP proxy but it is working. So I guess it is routed?
Edit: Provider’s support didn’t seem to understand what I’m talking about, so I’m still not sure if it’s routed… I see neighbor solicitation messages in icmp6 tcpdump for unused ipv6 addresses, but the containers’ IPv6 work, and no messages. All kernel ndp proxying is turned off btw.
Simply set LXD’s ipv6.address to a subnet within your system’s subnet and set ipv6.nat=false
IPv6 doesn’t support prefixes larger than (subnets smaller than) /64 with stateless auto configuration (SLAAC), so you need to manually configure IPv6 in each container (unique address; netmask and gateway same as lxd) or set ipv6.dhcp.stateful=true on the LXD network and use a dhcpv6 client inside the instance.
As a suggestion for the development of LXD, I think work should be done to support smaller subnets, because most VPS’s come with a /64 prefix. In fact it would be cool if the lxd init script could auto detect the system’s ipv6 and ask if you want to use a portion of it.
Normal IPv6 allocation uses SLAAC which relies on EUI64 to compute an IPv6 address from your MAC address. This method cannot work with subnets smaller than a /64 as there simply isn’t enough bits left to encode the address through EUI64 (which as the name implies, will encode a mac address within 64bit of IPv6 address).
Smaller subnets should be fine if you turn on stateful DHCPv6 as dnsmasq will then operate normal DHCP rather than rely on EUI64, but doing that will/may require changes to the network config inside each container you create so they perform full stateful DHCPv6.
It’s also worth noting that the IPv6 allocation RFC (rfc6177) specifies an allocation of /56 to end users or /48 for larger sites.
Providers giving you a single /64 (not even routed separately from the /64 for the physical host) are not following the recommended allocation for IPv6 subnets to customers.
You can also normally reconfigure your hosts external interface to have a single IP in that single /64 block but configure the single address as a /128 address, then you can use the rest of the /64 on the lxdbr0 network, with stateless slaac rather than needing to use ipv6.dhcp.stateful=true
This has been done a couple of times on this forum with Hetzner as they route the /64 subnet direct to the host without needing an NDP response from the host for each IP.
This is where it really helps to have an ISP/Host that is following IPv6 deployment recommendations, and providing an option to route addition subnet(s) to you host machine. Then your host can act as a router and you can then allocate the additional subnets to LXD’s network. That way there’s no need for messing about with proxy NDP (this is where you tell the host to artificially reply to NDP enquiries for a particular IP on a particular external interface that is not actually bound on the LXD host).
Proxy NDP can be used to ‘advertise’ specific IPs that LXD is using on its internal network to the wider external network when the ISP only provides a single /64 subnet at L2 to the host. This allows traffic for those IP to arrive at the LXD host’s external interface, at which point if the LXD host has the correct routes locally it will then route the packets into the LXD network as normal.
We provide a routed NIC type that will allow this occur. However because Linux’s proxy NDP support only allows single IPs to be advertised, rather than an entire subnet, the routed NIC doesn’t support SLAAC/DHCPv6, and IPs must be statically allocated in LXD and configured inside the container.
See
The other alternative is to run a separate daemon, something like ndppd which can be configured to artificially respond to all NDP queries for a particular subnet:
I suppose if docker uses a single IP per container and adds a static route to the host, then you could also use proxy NDP on the lxdbr0 to advertise the addition single IPs to the lxdbr0. Its a bit of a faff though and having multiple /64 subnets would be a lot easier.
 ! But not Debian or Rocky Linux images.
! But not Debian or Rocky Linux images.