Hello, I’m playing with a 3 node LXD cluster. When I reboot one of the nodes all lxc/lxd commands hang until that node comes back.
Is there a way to issue commands on the remaining node or nodes if one goes missing?
Hello, I’m playing with a 3 node LXD cluster. When I reboot one of the nodes all lxc/lxd commands hang until that node comes back.
Is there a way to issue commands on the remaining node or nodes if one goes missing?
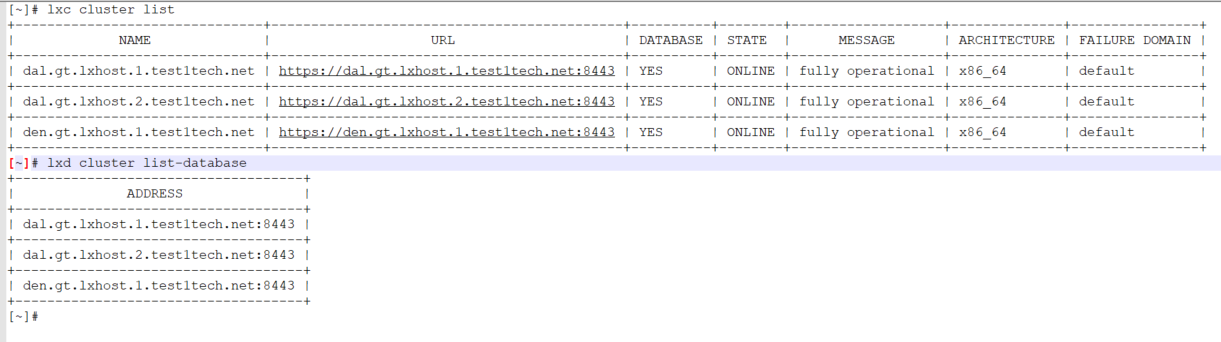
Can you show lxc cluster list and lxd cluster list-database?
Here is that output. All hostnames are internally resolvable. Everything works until I reboot one of the nodes. Then any lxd/lxc commands hang until that node comes back alive.
Ok, nothing looks wrong so far.
Can you show lxd sql local "SELECT * FROM raft_nodes;" on each system?
hostname dal.gt.lxhost.2.test1tech.net [~]# lxd sql local "SELECT * FROM raft_nodes;" +----+------------------------------------+------+ | id | address | role | +----+------------------------------------+------+ | 1 | dal.gt.lxhost.1.test1tech.net:8443 | 0 | | 2 | dal.gt.lxhost.2.test1tech.net:8443 | 0 | | 3 | den.gt.lxhost.1.test1tech.net:8443 | 0 | +----+------------------------------------+------+ [~]# hostname dal.gt.lxhost.1.test1tech.net [~]# lxd sql local "SELECT * FROM raft_nodes;" +----+------------------------------------+------+ | id | address | role | +----+------------------------------------+------+ | 1 | dal.gt.lxhost.1.test1tech.net:8443 | 0 | | 2 | dal.gt.lxhost.2.test1tech.net:8443 | 0 | | 3 | den.gt.lxhost.1.test1tech.net:8443 | 0 | +----+------------------------------------+------+ [~]# c]# hostname den.gt.lxhost.1.test1tech.net [~]# lxd sql local "SELECT * FROM raft_nodes;" +----+------------------------------------+------+ | id | address | role | +----+------------------------------------+------+ | 1 | dal.gt.lxhost.1.test1tech.net:8443 | 0 | | 2 | dal.gt.lxhost.2.test1tech.net:8443 | 0 | | 3 | den.gt.lxhost.1.test1tech.net:8443 | 0 | +----+------------------------------------+------+ [~]#
Can you enable debug mode on all 3 nodes:
sudo snap set lxd daemon.debug=true; sudo systemctl reload snap.lxd.daemon
Then when you restart one of the nodes, can you show the output from sudo tail -f /var/snap/lxd/common/lxd/logs/lxd.log when you try and run a command on another system.
Yeah, so far it looks like you have 3 properly configured cluster nodes all acting as database voters so this should definitely be able to tolerate the loss of one of them.
I think I know what happened here. If I issue the commands immediately after losing a node it seems to hang. If I give it some more time to realize an error state it seems like everything is fine.
That does bring up one more question. If I lose two nodes out of a 3 node cluster that leaves me with 1 node that I cannot really do anything with. Such as bring up backup containers launch new ones or anything that would modify the database.
Tests seem to indicate is this correct?
Am I better off in this small scenario using remotes and managing things like placement manually?
Right, losing a node will take about 15s before the cluster treats it as gone and reacts quickly again.
If you lose two nodes then the database will refuse to answer queries until a second node is back up. It always needs a quorum of nodes.
In the event of a permanent failure of the two nodes, you can use lxd cluster recover-from-quorum-loss which effectively de-clusters your machine.
Is there a method to rebuild a cluster from one machine?
Yes, you use that lxd cluster recover-from-quorum-loss to get its database back online, you then delete all references to anything on any of the other nodes that may be left, then you can add them back once they’re clean and had LXD reinstalled.
You only ever need to do this for cases where a majority of your DB nodes have gone away which should pretty much never happen though.
Thanks for the info! I will play with this more.