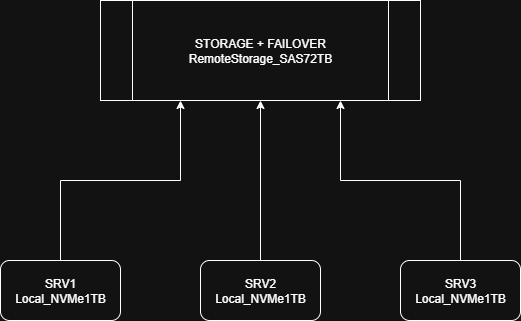
I have 3 servers with local NVMe storage (SRV1–3) and one separate server with 72TB SAS storage. I’d like to use that one only as a backup node — so that if any of the main servers go down, containers would start there.
All nodes are running:
ZFS as the filesystem
Alpine Linux
Ceph feels too heavy, and unfortunately Linstor doesn’t work on Alpine.
Is it possible to set up this kind of scenario with Incus? Or something close to it?
Thanks in advance!
I agree that having the backup node not be part of the main cluster is a good thing; incus clustering can fail in ways that lock up the whole cluster.
Option 1: periodically replicate the containers of interest to the backup node, using incus copy --refresh src:foo dst:foo. This should use optimized volume transfer, as long as both sides are ZFS, and the initial copy included a snapshot.
You can set up incus to schedule automatic snapshot creation, but you have to script and monitor the incus copy operations yourself.
It would be up to you to handle failover, i.e. start the instance on the backup node if the main cluster fails. This can very easily lead to split brain if the application ends up diverging state, which will be impossible to reconcile (you’ll have to lose data from one or the other), so IMO automating this failover is a bad idea without hardware support - e.g. the backup node has the ability to control the power into the main cluster (“STONITH”).
Each replica is always going to be somewhat behind the original, i.e. from when the last copy operation took place.
However this is a simple and robust solution.
Option 2: run a separate instance of your application on the “failover” cluster, on a different IP address - i.e. “live-live” operation. Then run a load balancer which runs on any two nodes, and a floating IP address which moves between them (e.g. keepalived). Point your clients at the load-balancer.
This will give you true HA with immediate failover, but it’s a lot more work to set up and maintain. It also works best for applications which are stateless.
Regarding Linstor: it’s just a java application, so I expect it could be made to work under Alpine. The issues you’ll have are (1) compiling the drbd9 kernel module, and (2) I don’t think you’ll be able to share a replicated volume across two separate incus clusters. You might be able to use Linstor’s scheduled backups and backup shipping (I’ve not tested that), but then you’re back to behind-time snapshot replicas just like ZFS replication.
Thanks for the detailed reply — really appreciate the insight.
You’re right that option 1 (using incus copy --refresh) is simple and robust. The problem in my case is that new containers are created frequently, and manually scripting snapshot/replication logic per container doesn’t scale well. I also need something closer to real-time; delayed replication isn’t ideal for our use case (we did look into zrepl for ZFS-level sync, but again — it’s not real-time).
Option 2 (live-live with a load balancer) also doesn’t fit, since most of our workloads are stateful (like ERP systems), and simply shifting IPs via keepalived wouldn’t handle storage consistency or running state.
What we’re actually looking for is something closer to how LXD handled shared storage with external systems like Dell PowerFlex (link).
In that setup, storage is shared (via NFS/iSCSI/etc.), and the container can be restarted on another node if the original one goes down — with no replication needed, since the storage is common.
Unfortunately, Incus doesn’t seem to support this kind of shared-storage failover without Ceph.
We’d love to see a minimal shared-storage HA mode — without requiring a full Ceph setup — especially for environments like ours using Alpine Linux and ZFS.
Is there any technical reason why Incus can’t support this kind of shared-storage HA model (without Ceph)?
Could something like this be implemented using NFS or a custom storage backend?
we also use the scenario @candlerb describes.
I don’t see an issue using scripts for the copy --refresh. Just use the rest api or cli commands with json output to dynamically iterate over all the running instances.
simlified example:
for c in $(incus list --format=json | jq -r '.[] | select(.state.status == "Running") | .name'); do
incus copy $c $TARGET_HOST: --refresh
done
What is still on my todo/wish list is to also find a way for a shared storage, similar to an ESX mounting isci devices from more than one node. incus cluster is not able to handle that scenario today and NFS is something I would like to avoid for good reasons and I doubt it’s supported to store the containers - you would also loose all the fantastic features inherited from zfs/btrfs.
That’s incorrect, Incus supports this through the lvmcluster storage driver.
This works with all kind of shared block storage rather than just PowerFlex. We commonly use that with DELL customers running PowerFlex or PowerMax for storage but also with storage solutions from HP, Hitachi and others. Basically anything that can expose the same block device / LUN on all servers is supported.
My setup uses ZFS, so lvmcluster isn’t an option, Linstor is not supported on Alpine Linux, and Ceph is quite heavy to set up and maintain
I have several compute nodes with NVMe and one storage node with SAS. Containers run on compute nodes. I’m planning to test syncing them to the storage node using incus copy --refresh via API.
In case a compute node fails, I want to be able to automatically start the container on the storage node with up-to-date data.
Do you see any issues with this approach?
Are there plans for native support of this kind of ZFS-based failover or automated replication?
Thanks for the great work on Incus — it’s been really interesting to explore!
No plans for automatic copy on our end but it’s reasonably straightforward to drive through API and it’s pretty commonly done by some of our larger users.
Thanks! Good to know this pattern is already used in production.
I’ll proceed with testing the copy automation via API and will share any useful findings. Appreciate the response!