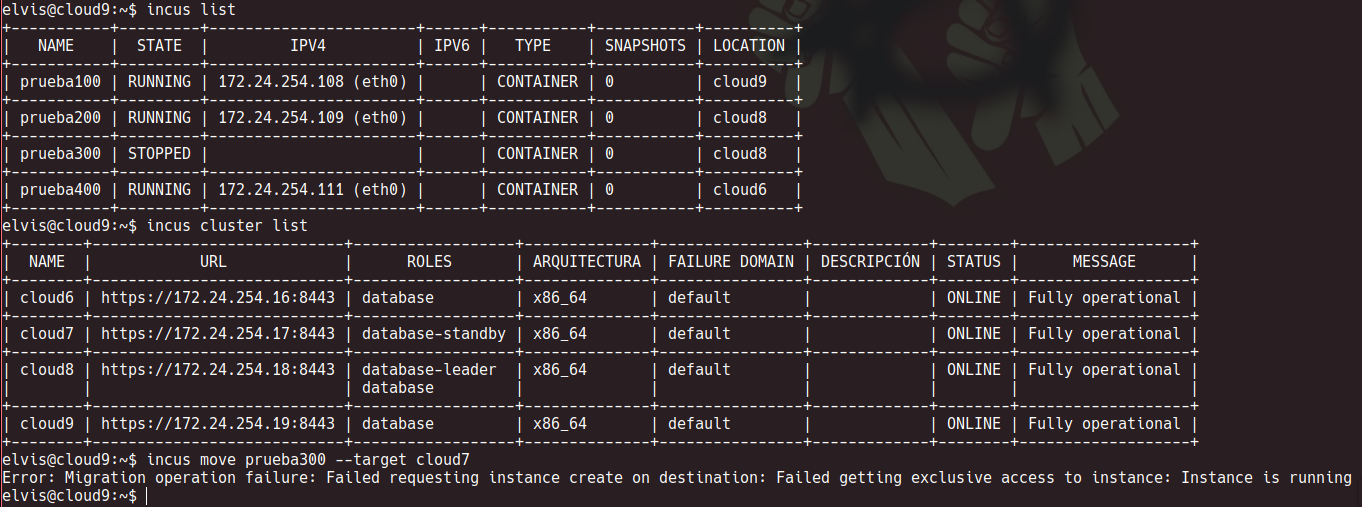
It’s possible that the container isn’t quite fully stopped due to a kernel bug.
You may want to look at ps fauxww and look for anything resembling a leftover of that container, of particular note anything that’s stuck (D or Z state).
thanks, to replicate the error have to down the port in switch that it’s had connected one cluster node with instances running, move the instances in error to online nodes, recover the node down, and finaly try to move instance to recovered node. With that context how can “clean” the node recovered using incus API?