Good luck mate, everything seems to be in order maybe it just needs a good reboot.
I replicated the issue locally. I’m going to look deeper.
Okay, so I really don’t know what’s going on, but after looking at this in depth I actually realized that your database is somehow corrupted, although I don’t understand how.
However, you can try a quick harmless procedure which is likely to work:
- Backup your current database directory, e.g.
cp -a /var/lib/lxd/database /var/lib/lxd/database.after-upgrade. Do that on all nodes. - Remove the
logs.db:rm /var/lib/lxd/database/global/logs.db. Do that on all nodes. - Start your LXD daemons, e.g.
systemctl start lxd. Do that on all nodes.
Note that you don’t need to reboot anything. Just do the steps above and let me know.
freeekanayaka, I tried about, no difference. Seems to be socket comminuication issue to me
lxc list cluster --debug
DBUG[02-08|18:45:26] Connecting to a local LXD over a Unix socket
DBUG[02-08|18:45:26] Sending request to LXD method=GET url=http://unix.socket/1.0 etag=
Any way to test communication between cluster sockets.
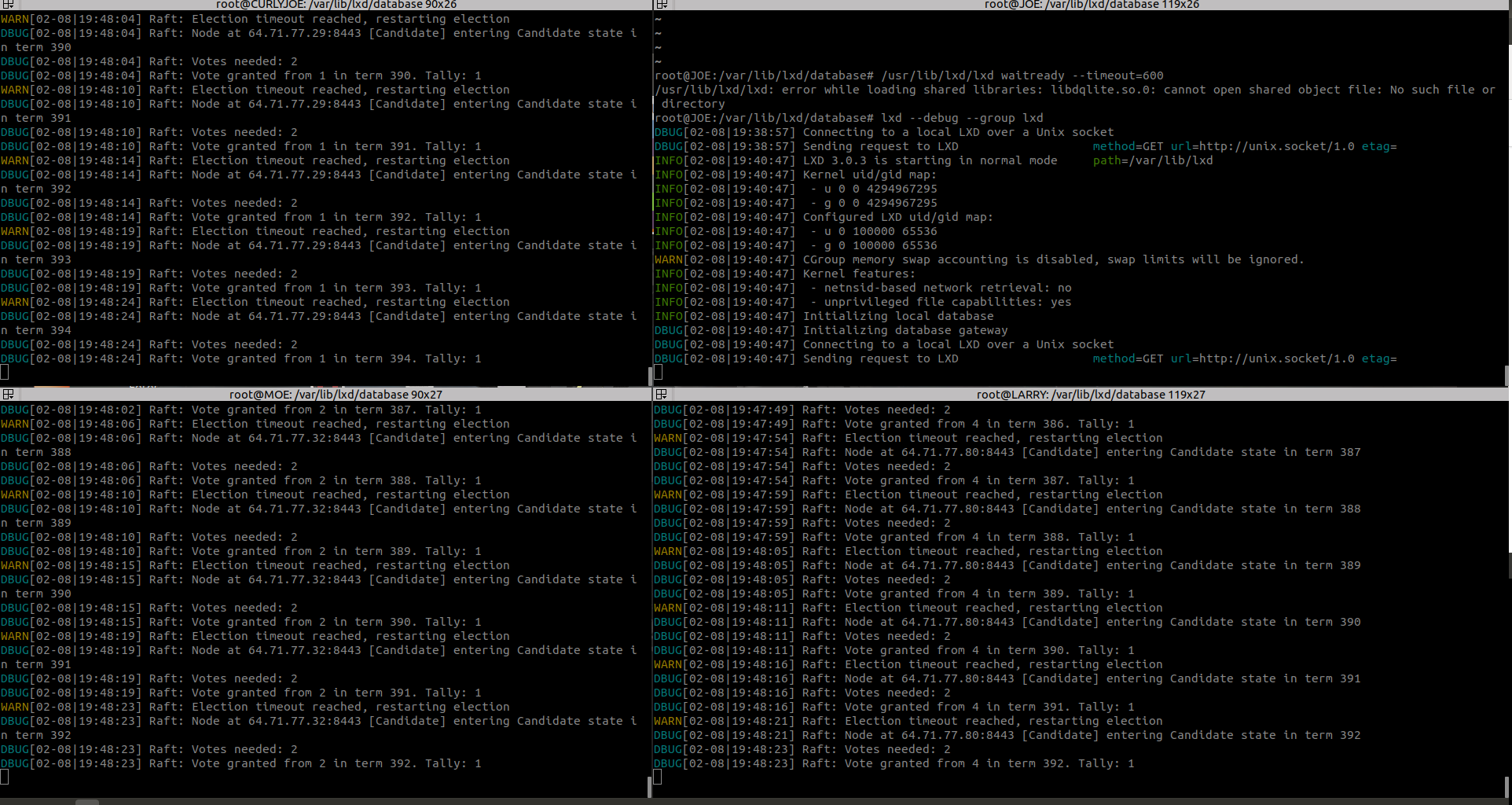
Everything seems to point to a socket problem after upgrade which seems to be a pretty common problem. LXD seems to know that it wants to talks to other server, but can’t open the socket. Last time this happen it was a permission issue, but that does not seem to work here.
If I dont reboot server the LXC container part seems to work. But lxd does not start and then lxc wont either. Is there any way to start containers without lxd. Or any way I can break a server off a cluster if it is in a cluster. I could then move the containers around to new servers.
On Curlyjoe
lxd --debug
DBUG[02-08|21:24:09] Connecting to a local LXD over a Unix socket
DBUG[02-08|21:24:09] Sending request to LXD method=GET url=http://unix.socket/1.0 etag=
On Joe:
DBUG[02-08|21:30:48] Dqlite: connection failed err=no available dqlite leader server found attempt=4
DBUG[02-08|21:30:49] Dqlite: server connection failed err=failed to establish network connection: 503 Service Unavailable address=64.71.77.29:8443 attempt=5
DBUG[02-08|21:30:49] Dqlite: server connection failed err=failed to establish network connection: 503 Service Unavailable address=64.71.77.32:8443 attempt=5
DBUG[02-08|21:30:49] Dqlite: server connection failed err=failed to establish network connection: 503 Service Unavailable address=64.71.77.80:8443 attempt=5
DBUG[02-08|21:30:49] Dqlite: connection failed err=no available dqlite leader server found attempt=5
DBUG[02-08|21:30:50] Dqlite: connected address=64.71.77.29:8443 attempt=6
INFO[02-08|21:30:50] Initializing storage pools
DBUG[02-08|21:30:50] Initializing and checking storage pool “local”
DBUG[02-08|21:30:50] Checking ZFS storage pool “local”
EROR[02-08|21:30:50] Failed to start the daemon: no “source” property found for the storage pool
INFO[02-08|21:30:50] Starting shutdown sequence
INFO[02-08|21:30:50] Stopping REST API handler:
INFO[02-08|21:30:50] - closing socket socket=[::]:8443
INFO[02-08|21:30:50] - closing socket socket=/var/lib/lxd/unix.socket
INFO[02-08|21:30:50] Stopping /dev/lxd handler
INFO[02-08|21:30:50] - closing socket socket=/var/lib/lxd/devlxd/sock
INFO[02-08|21:30:50] Closing the database
DBUG[02-08|21:30:50] Dqlite: closing client
DBUG[02-08|21:30:50] Stop database gateway
INFO[02-08|21:30:50] Stopping REST API handler:
INFO[02-08|21:30:50] Stopping /dev/lxd handler
INFO[02-08|21:30:50] Stopping REST API handler:
INFO[02-08|21:30:50] Stopping /dev/lxd handler
INFO[02-08|21:30:50] Unmounting temporary filesystems
INFO[02-08|21:30:50] Done unmounting temporary filesystems
INFO[02-08|21:30:50] Saving simplestreams cache
INFO[02-08|21:30:50] Saved simplestreams cache
Error: no “source” property found for the storage pool
root@JOE:/home/ic2000#
I need to get a diagnosis and a strategy going forward. I just cant erase LXD and call it a day. I need to either fix it, or move to another cluster and move it over. So far, I have seen LXD do something similar to this twice whenever a Ubuntu upgrade happens. There has to be a solution. More things seem to be working than not. It seems to need something to jump start it.
I’m having the same problem did you find a fix.
I lost a connected server with no way to recover it and now the main server’s lxd services won’t start as it can’t find the second server.
I’ve had the same problem in the past and a reboot of the second server fixed problem but now it’s dead and i’m stuck now.
I just don’t know how to break the link to the second server if I cant get into the lxc command-line tool
This might help you to get to files, its possible to mount containers folder structure and get to info if using zfs:
sudo zfs list
sudo zfs mount zpool/containers/containername
cd to /var/lib/lxd/…/…/…/ “mount point listed in zfs list”
cd rootfs "and you into systems files
However, as you said a fix is better starting again is not preferable any help on a solution would be greatly appreciated 
I was wandering if i was to reinstall my apt LXD install would i lose all the containers Did you have to resort to a fresh start was this the case?
Ben