The zfs-pool is default as per lxd-init and uses the single NVME disk on its own partition. (We are about to expand this with more disk-devices soon to mitigate future problems)
The problem description
One container is running a websocket service (ws://) accepting about 250 tcp connections normally.
The problem manifest itself such as that the websocket service “chokes” gradually as connections ramp up. Its starts as early as at about 30-40 and eventually only responds sporadically.
What about the service?
I would have suspected the service itself to be the culprit, if it wasn’t that the “choking” behavior seem to propagate to the container itself at tiems. E.g. keyboard entries, commands and outputs completely freezes for about a few seconds now and then and then resumes.
Observations and actions
None of the other services or containers has this problem.
The disk is at about 60% usage and 35% frag.
No iowait can be observed.
CPU utilization is 7/16 (E.g. shouldn’t be an issue)
We have replaced the container (re-install) but the problems come back.
We get the same problem on a different identical host.
Only one of the CPU:s is running at 100% (out of 16) so the blocking behavior shouldn’t be the cause of a CPU exhaustion.
I’ve seen this behavior before (In this thread) and at that point I thought the zfs component would be the issue. I managed at that point to get out of the situation by removing the service itself. But now that I got to this situation again, on a completely different system, I need to understand on how to pursue this issue fundamentally.
My next step - my questions.
I will try to run the service directly on the host, to see if LXD is the issue here but I have some questions:
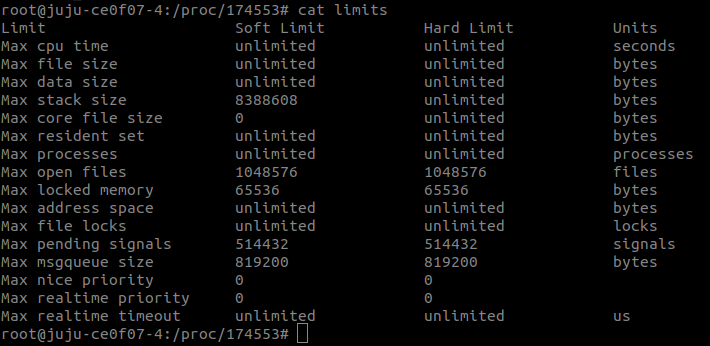
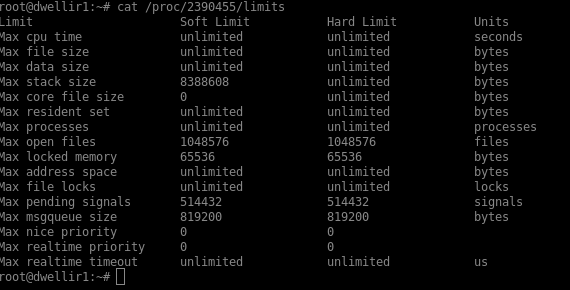
Is there any default capacity constraints on a lxd container which I might be hitting on this node?
Is there any recommended settings on zfs pools/volumes that is intended to be used with lxd containers on SSD/nvme such as:
zfs set primarycache=metadata lxdhosts/containers/juju-46be60-0
zfs set secondarycache=metadata lxdhosts/containers/juju-46be60-0
Is there any professional help to get on LXD/ZFS to assist me in finding the problem at hand?
I’m not seeing anything above which really suggests that ZFS is the issue here, your service doesn’t seem to be I/O dependent so it seems more likely that you’re hitting some kind of max_connection/max_open limit.
Anything odd looking in dmesg? How many open fds does your daemon have?
I’m on the same track @stgraber here - but since I’ve seen it before. I want at good strategy to rule it out.
The scary thing, is that the service at times runs all fine for days or even weeks. This is indeed an indication that its the service-code that causes this, but… yeah.
Also, I would love to know what tools I should use to figure this out. I’m using combinations of “dstat”, “top”, “htop”, iotop", “systemd-cgtop” to query and look for patterns. They don’t give the same view, so I would love to know how the pros do it to determine load. For example to be able to look at specific disks, pools, etc. to be able to rule out disk.
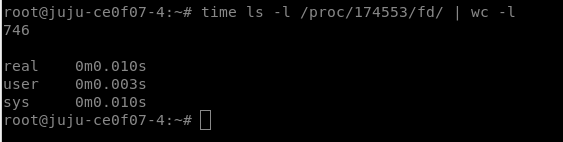
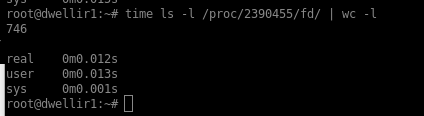
The daemon is about 800+, but not particular high. What we notice is a huge difference in time when doing “lsof” on the container vs lxc-host as pictured below. This is interesting for us as it now turns our eyes towards lxd rather than zfs. Thanx alot for this pointer.
Below the timing of the same process in vs outside of the container. Notice the huge difference.
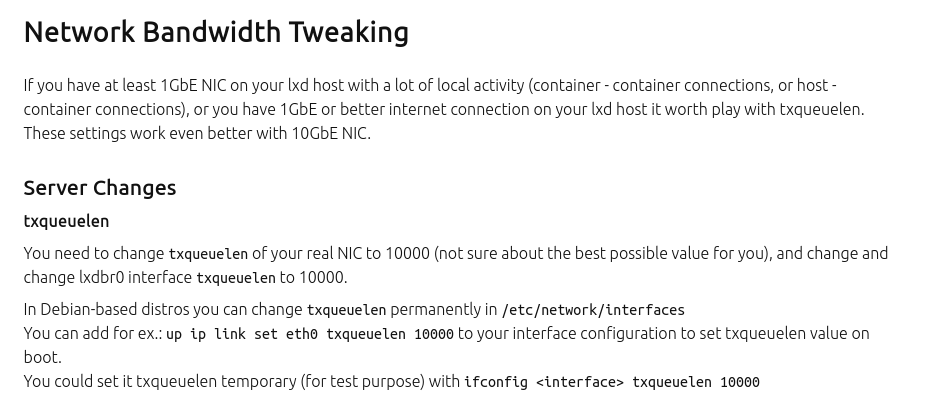
Worth mentioning is that we applied “sysctl -p /etc/sysctld.d/99-zfs.conf” on the host without a boot. Perhaps we need to boot the node to get the settings below to apply fully?
The only thing I can come to mind now is that we have not applied the “tzqueuelen” on the server and we didn’t reboot after applying the kernel parameters. This is also something we will do, but what are your thoughts on that?
Another questions on LXD, would kernel settings be applied to containers as part of a sysctl -w or as set in /etc/sysctl.conf or would this only matter to the host?