Hello everyone, how are you?
I hope you can help me with this problem.
I’m an infrastructure analyst at a company that uses LXD/LXC on most of its machines, with many containers. I am positioned in the Backups/Restore field, which is new for me, in addition to having only 3 years as a Linux analyst.
Well, we have two Backup servers where one is a mirror of the other, and as we don’t have the Tapes Library it was decided to do the Offline Backup in the Cloud. The Script for this backup was created three years before I joined the Company.
Until I joined, no one knew the condition of the backups, how to use them and what procedures were used to restore them.
Well, I decided to carry out this task, and within the scope of local servers, everything went smoothly.
The problem is with Cloud Backup.
Note that I can download the system files. However, the root ids changed to 1000000.
The company’s policy is to keep containers in non-privileged mode for security, which causes this fact.
However, when this image is imported into LXC, most processes do not work, as the host machine’s LXD/LXC does not recognize the IDS mapping and internally to the container they remain as 1000000.
This means that the container’s internal processes do not work properly.
I don’t know if it’s appropriate, but as the Backup was made from the file system, the process I use to perform the Restore after the Download is:
1- Once I have the backup.yaml and matadata.yaml, as well as the root fs, I mount a .tar.gz file.
2- using the import command, I import this container via tar.gz into LXD/LXC, creating an image of it.
3-Launch this image as a container via lxc launch.
The Container even starts, however all files have their uids and gids changed to 1000000.
I’ve already tried doing it on different Hostnodes as well as on the same hostnode.
The result is always the same.
Below I will post the information that I believe is necessary to help with the troubleshoot.
# lxc version
Client version: 5.0.3
Server version: 5.0.3
Lxc Container config
architecture: x86_64
config:
image.architecture: amd64
image.description: Ubuntu jammy amd64 (20230503_07:42)
image.name: ubuntu-jammy-amd64-default-20230503_07:42
image.os: ubuntu
image.release: jammy
image.serial: "20230503_07:42"
image.variant: default
security.privileged: "false"
volatile.base_image: 156f8cf4f381f067fca3d29c766222b5c75680b89c6d73e5f5e70a6128df2e15
volatile.cloud-init.instance-id: 268b2e3d-559a-4dec-a63f-538ad8ffa6d0
volatile.eth0.host_name: vethf81e05d0
volatile.eth0.hwaddr: 00:16:3e:53:55:fe
volatile.idmap.base: "0"
volatile.idmap.current: '[{"Isuid":true,"Isgid":false,"Hostid":1000000,"Nsid":0,"Maprange":1000000000},{"Isuid":false,"Isgid":true,"Hostid":1000000,"Nsid":0,">
volatile.idmap.next: '[{"Isuid":true,"Isgid":false,"Hostid":1000000,"Nsid":0,"Maprange":1000000000},{"Isuid":false,"Isgid":true,"Hostid":1000000,"Nsid":0,"Map>
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":1000000,"Nsid":0,"Maprange":1000000000},{"Isuid":false,"Isgid":true,"Hostid":1000000,"Nsid":>
volatile.last_state.power: RUNNING
volatile.uuid: 1cc88a9f-3efe-45c7-9ecf-1cbb3bc2a7df
volatile.uuid.generation: 1cc88a9f-3efe-45c7-9ecf-1cbb3bc2a7df
devices: {}
ephemeral: false
profiles:
- default
stateful: false
description: ""
created_at: 2024-04-04T14:43:00.51204393Z
name: zabbix-restore-test00
status: Running
status_code: 103
last_used_at: 2024-05-23T14:07:02.87278368Z
location: none
type: container
project: default
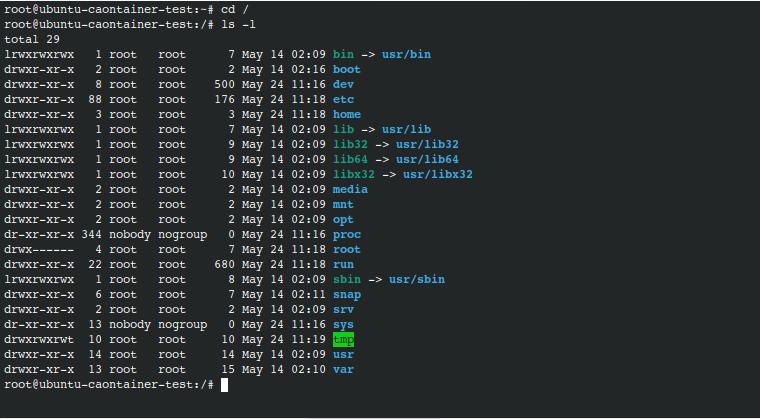
Here is a screenshot from inside the container.
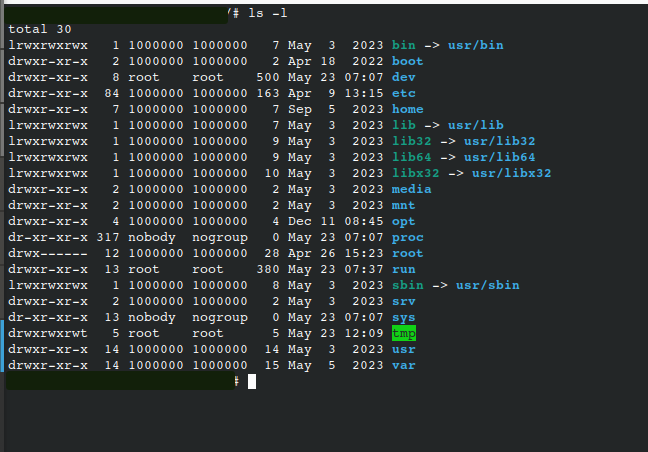
The screen shot from cloud download file system:

:~# cat /etc/subuid
ubuntu:100000:65536
linuxuser:165536:65536
:~# cat /etc/subgid
ubuntu:100000:65536
linuxuser:165536:65536
If you guys need more information let me know.
Hope you can help me with this.