I have 2 servers on Digital Ocean
- node1
- node2
I had no problem creating 2 projects on each NODE
- tenant1
- tenant2
my use case involved use of Wireguard installed on each NODE and using
wireguard’s allowed-ips to add each NODE’s subnets (incus bridge networks) to be accessible via VPN tunnel from node1 ↔ node2
But I ran up against something I’m not sure I understand.
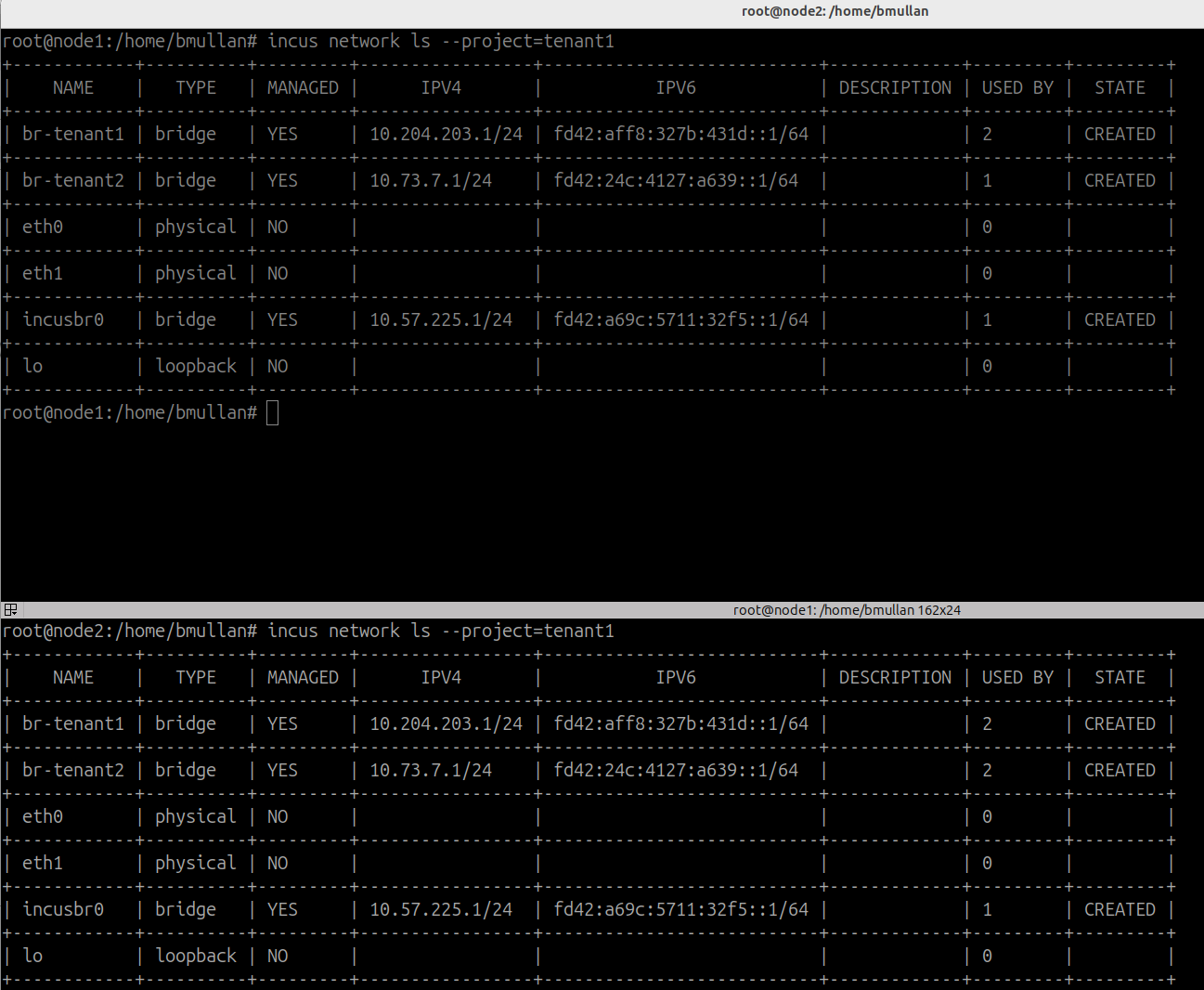
Checking the project named “tenant1” on each server NODE:
Top picture is from the Digital Ocean server named node1 and shows
result of executing:
incus network ls --project=tenant1
Bottom picture is from the Digital Ocean server named node2 and shows
result of executing:
incus network ls --project=tenant1
on both node1 and node2 despite being separate Digital Ocean server instances
node1
- br-tenant1 = 10.204.203.1/24
- br-tenant2 = 10.73.7.1/24
node2
- br-tenant1 = 10.204.203.1/24
- br-tenant2 = 10.73.7.1/24
the br-tenant1 ip address on node1 is identical to the br-tenant1 ip address on node2 ??
same for br-tenant2 on both server/NODES
Problem:
on each Wireguard VPN Peer the “allowed-ips” cannot permit the same subnet on two separate Nodes or tunnel traffic will only be directed to only 1 node’s incus subnet (either node1 or node2)
First, I was surprised they were identical on 2 separate servers as I had thought they would be more random IP addressed than that.
I copied & used the same script to create the projects on both node1 & node2.
And that script does not configure any IP address for the project bridges?
Can anyone help me understand how 2 separate servers are getting identical 10.x.x.x/24 addresses assigned to incus project bridges on each server?
note1:
yes I understand that in this test environment config it might be possible for this to occur
but
I’ve repeated this 3-4 times and the results are the same every time.
Each time both server/nodes end up with identical IP addresses for the incus bridges assigned to each project on each node
note2:
I have not looked at using OVN in this yet but have seen some comments that OVN might be a way to resolve this conundrum.
thanks for any ideas/thoughts