I’m planning to migrate my LXD cluster with microceph storage to Incus stable (6.0).
My cluster built on top of 7x RPI4 SBCs with Ubuntu 23.10 as host OS.
Before migrate this cluster I tried to evaluate migration process with virtual lab built with 3 Ubuntu 23.10 VMs which is partially emulate my production cluster. However, I was not able to complete migration due to migration fail. lxd-to-incus process completes successfully on slave nodes but fails on primary node then with the following error:
Error: Failed to restore "vm-01": Failed to start instance "dns-01": Failed to run: rbd --id admin --cluster ceph --pool lxd map container_infra_dns-01: exit status 1 (rbd: warning: can't get image map information: (13) Permission denied
rbd: failed to add secret 'client.admin' to kernel
rbd: map failed: (1) Operation not permitted)
All nodes in Incus cluster remain in “EVACUATED” state after that.
Test environment configuration:
3x Hyper-V VMs with 4 GB RAM; each VM has dedicated virtual disk for ceph cluster.
sudo lxd-to-incus
=> Looking for source server
==> Detected: snap package
=> Looking for target server
==> Detected: systemd
=> Connecting to source server
=> Connecting to the target server
=> Checking server versions
==> Source version: 5.21.1
==> Target version: 6.0.0
=> Validating version compatibility
=> Checking that the source server isn't empty
=> Checking that the target server is empty
=> Validating source server configuration
The migration is now ready to proceed.
A cluster environment was detected.
Manual action will be needed on each of the server prior to Incus being functional.
The migration will begin by shutting down instances on all servers.
It will then convert the current server over to Incus and then wait for the other servers to be converted.
Do not attempt to manually run this tool on any of the other servers in the cluster.
Instead this tool will be providing specific commands for each of the servers.
Proceed with the migration? [default=no]: yes
=> Stopping all workloads on the cluster
==> Stopping all workloads on server "vm-01"
==> Stopping all workloads on server "vm-02"
==> Stopping all workloads on server "vm-03"
=> Stopping the source server
=> Stopping the target server
=> Wiping the target server
=> Migrating the data
=> Migrating database
=> Writing database patch
=> Running data migration commands
=> Cleaning up target paths
=> Starting the target server
=> Waiting for other cluster servers
Please run `lxd-to-incus --cluster-member` on all other servers in the cluster
The command has been started on all other servers? [default=no]: yes
=> Waiting for cluster to be fully migrated
=> Checking the target server
=> Restoring the cluster
==> Restoring workloads on server "vm-01"
Error: Failed to restore "vm-01": Failed to start instance "dns-01": Failed to run: rbd --id admin --cluster ceph --pool lxd map container_infra_dns-01: exit status 1 (rbd: warning: can't get image map information: (13) Permission denied
rbd: failed to add secret 'client.admin' to kernel
rbd: map failed: (1) Operation not permitted)
2nd node
sudo lxd-to-incus --cluster-member
=> Looking for source server
==> Detected: snap package
=> Looking for target server
==> Detected: systemd
=> Connecting to the target server
=> Stopping the source server
=> Stopping the target server
=> Wiping the target server
=> Migrating the data
=> Migrating database
=> Cleaning up target paths
=> Starting the target server
=> Waiting for cluster to be fully migrated
=> Checking the target server
Uninstall the LXD package? [default=no]:
3rd node
sudo lxd-to-incus --cluster-member
=> Looking for source server
==> Detected: snap package
=> Looking for target server
==> Detected: systemd
=> Connecting to the target server
=> Stopping the source server
=> Stopping the target server
=> Wiping the target server
=> Migrating the data
=> Migrating database
=> Cleaning up target paths
=> Starting the target server
=> Waiting for cluster to be fully migrated
=> Checking the target server
Uninstall the LXD package? [default=no]:
incus cluster list output:
incus cluster list -f compact
NAME URL ROLES ARCHITECTURE FAILURE DOMAIN DESCRIPTION STATE MESSAGE
vm-01 https://vm-01:8443 database-leader x86_64 default EVACUATED Unavailable due to maintenance
database
vm-02 https://vm-02:8443 database x86_64 default EVACUATED Unavailable due to maintenance
vm-03 https://vm-03:8443 database x86_64 default EVACUATED Unavailable due to maintenance
I tried this migration twice building test environments from the scratch twice.
Can you try installing the ceph-common package on your systems if you don’t have it already?
Then once that’s there, you’ll want to make sure that the ceph and rbd commands are handled by that package and not microceph, I haven’t used snaps in a little while but there may be a snap unalias ceph and snap unalias rbd command you can use?
Basically the goal is to keep microceph working internally the way it is, but have normal ceph and rbd commands that do not rely on the snap. Those will then read from /etc/ceph, so you’ll need to make sure you have a /etc/ceph/ceph.conf and /etc/ceph/ceph.client.admin.keyring.
You should be able to find the current microceph versions of both of those files somewhere in /var/lib/microceph.
It’s a bit odd that microceph provides the rbd command while being fully aware that rbd map and rbd unmap don’t work due to snap confinement…
As for the lxd-to-incus run, it failed in the cluster restore stage which is all the way at the end of the migration, so if that cluster wasn’t a throw away test, you’d still be fine. You’d need to get the ceph and rbd commands to behave and then can manually run incus cluster restore NAME for each server and you’ll be done with the migration.
Thank you Stéphane for you quick reply and suggestions.
I have mixed results now after trying steps you suggested.
What I did:
restored VMs to snapshot before migration to Incus
installed ceph-common package to all nodes
added links to microceph config files (/var/snap/microceph/current/conf) into /etc/ceph
checked ceph health; rebooted nodes one-by-one to verify that ceph cluster works properly after installing ceph-common package
run lxd-to-incus
Migration was succussed without any issues. All nodes in incus cluster becomes available and all instances run after migration.
Good result ? Yes and No.
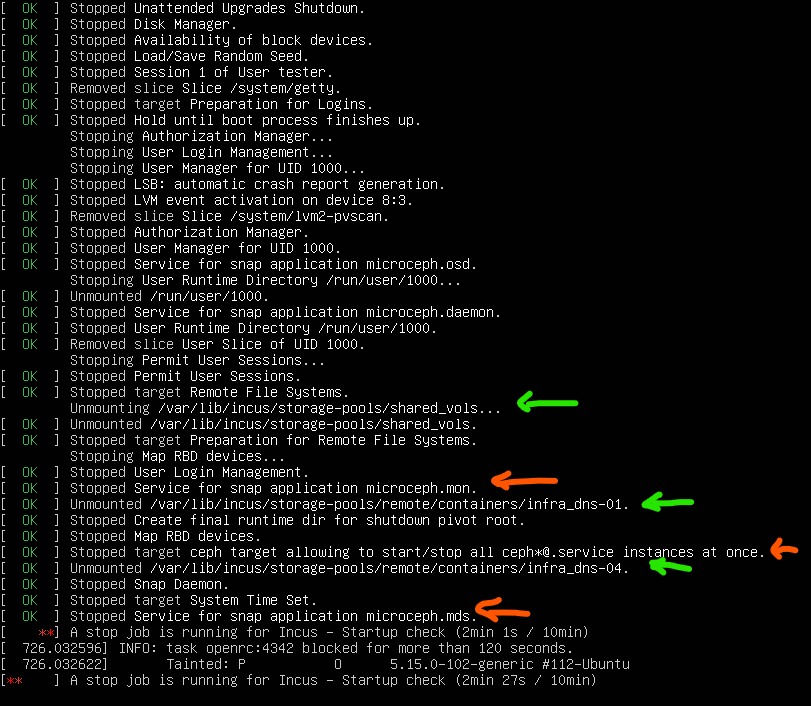
There is an issue wen node shutdowns/restarts. incusd can’t be properly shutdown. System kills it after timeout. The system constantly write error messages to console like:
Indeed sounds like your MicroCeph shouldn’t be shut down before Incus, though at the same time, a properly deployed Ceph with at least 3 monitors and enough OSDs to sustain a host failure should be able to handle this situation fine.
microceph populates ceph.client.admin.keyring file only on first node during cluster installation. all nodes contain ceph.keyring with the same. Absence of ceph.client.admin.keyring enforces ceph connectivity issues during single node shutdown when Incus is running:
copying publishing file ceph.client.admin.keyring file to /etc/ceph on all nodes resolves this issue
2. actually Incus unmounts all ceph volumes and storages in parallel with microceph daemons stopping. Not sure when instances were stopped.
3. Anyway, during full cluster shutdown (all nodes goes to power-off at the same time), at least 2 nodes stuck on Incus shutdown as it looses connectivity with ceph osds and monitors.
For a full cluster shutdown, I usually do incus cluster evacuate --action=stop NAME for each of the servers, so all instances get properly stopped ahead of time. Then hopefully there won’t be anything else needing ceph during the machine shutdown.
Then once the systems are back online and ceph is back to working order, you can use incus cluster restore to get all the instances back up and running.
I have briefly checked the similar approach by stopping all instances manually before full cluster shutdown. Incus does not block host shutdown in this case as well.