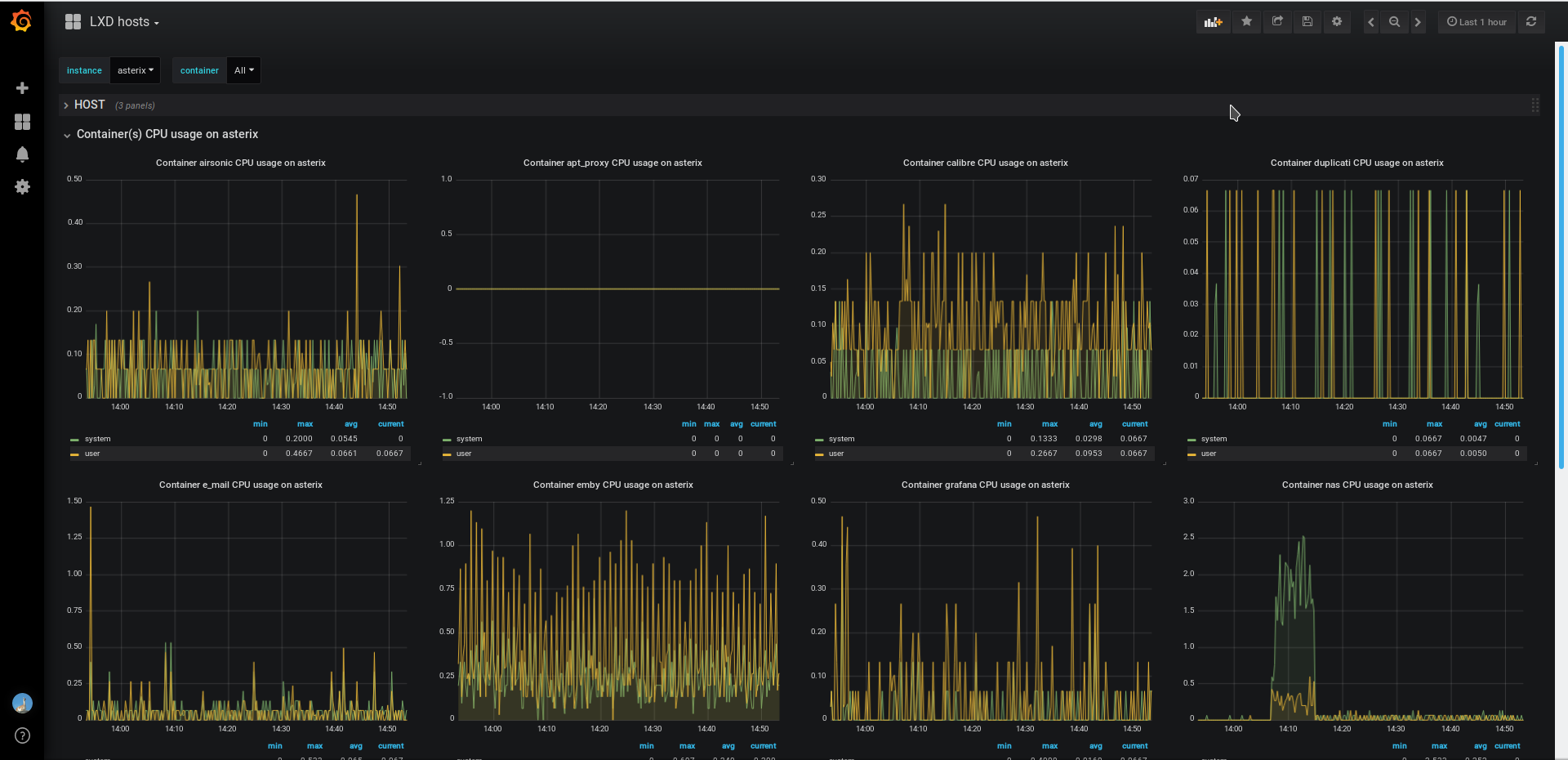
Every 5 minutes should be fine. It’s certainly not a cheap operation getting all that data from the kernel so you wouldn’t want to call it every few seconds, but every few minutes shouldn’t really be a problem.
To get an idea of what the API will give you:
curl --unix-socket /var/lib/lxd/unix.socket lxd/1.0/containers/c1/state | jq .metadata
{
"status": "Running",
"status_code": 103,
"disk": {
"root": {
"usage": 9805824
}
},
"memory": {
"usage": 111071232,
"usage_peak": 234029056,
"swap_usage": 0,
"swap_usage_peak": 0
},
"network": {
"eth0": {
"addresses": [
{
"family": "inet",
"address": "10.204.119.69",
"netmask": "24",
"scope": "global"
},
{
"family": "inet6",
"address": "2001:470:b368:4242:216:3eff:fef4:db69",
"netmask": "64",
"scope": "global"
},
{
"family": "inet6",
"address": "fe80::216:3eff:fef4:db69",
"netmask": "64",
"scope": "link"
}
],
"counters": {
"bytes_received": 57945,
"bytes_sent": 4876,
"packets_received": 417,
"packets_sent": 38
},
"hwaddr": "00:16:3e:f4:db:69",
"host_name": "vethSJ6ABH",
"mtu": 1500,
"state": "up",
"type": "broadcast"
},
"lo": {
"addresses": [
{
"family": "inet",
"address": "127.0.0.1",
"netmask": "8",
"scope": "local"
},
{
"family": "inet6",
"address": "::1",
"netmask": "128",
"scope": "local"
}
],
"counters": {
"bytes_received": 0,
"bytes_sent": 0,
"packets_received": 0,
"packets_sent": 0
},
"hwaddr": "",
"host_name": "",
"mtu": 65536,
"state": "up",
"type": "loopback"
}
},
"pid": 22156,
"processes": 29,
"cpu": {
"usage": 6312866518
}
}

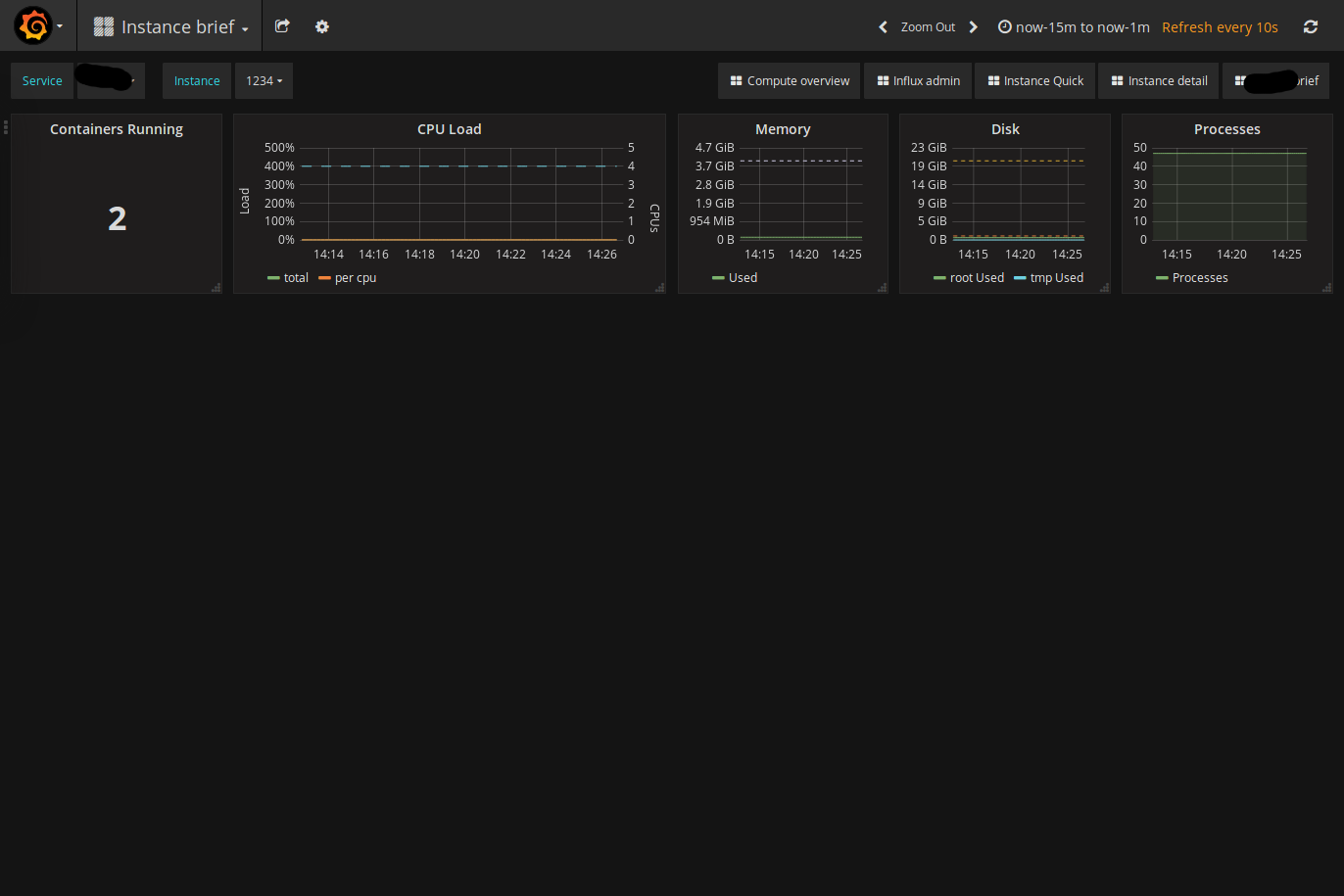

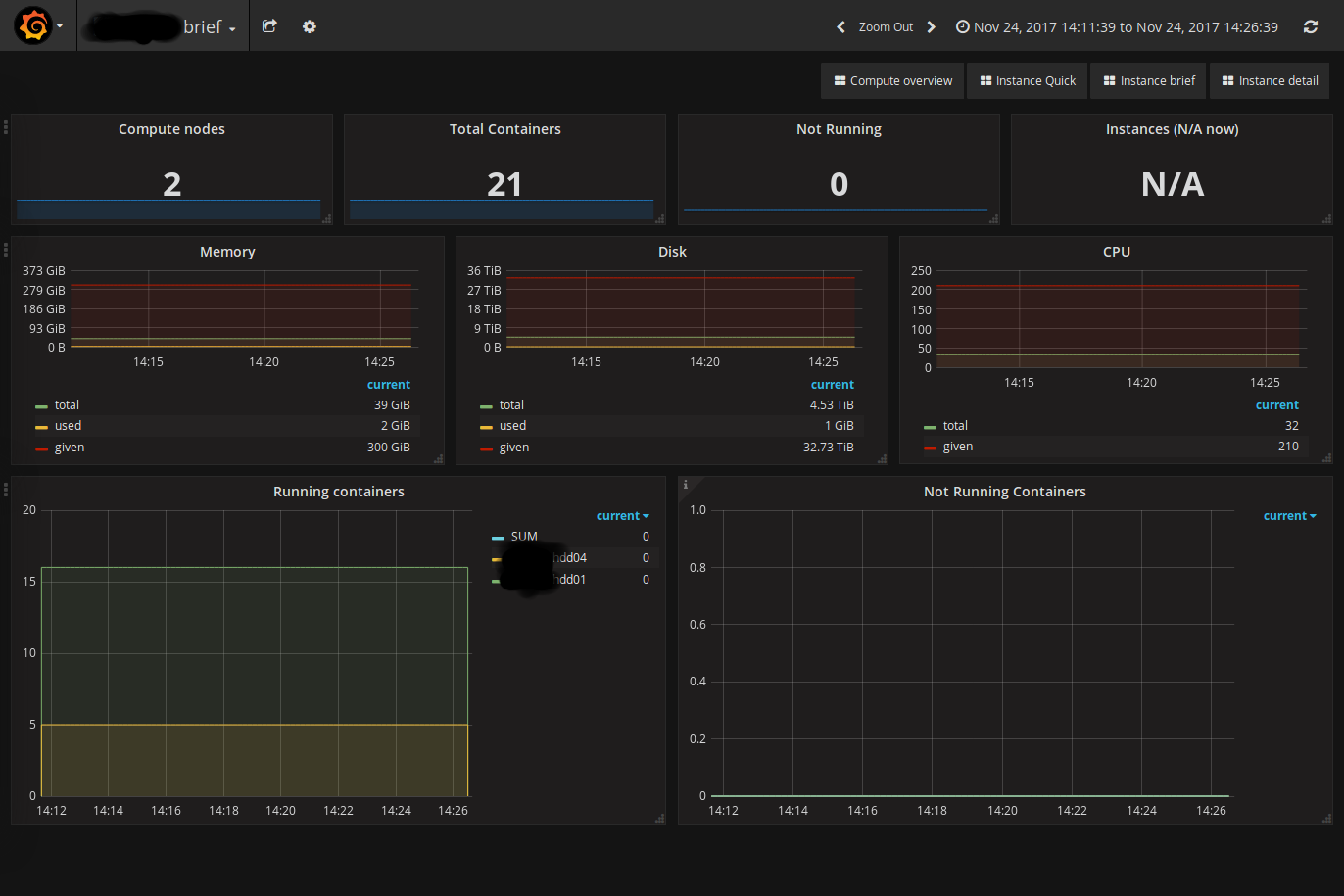
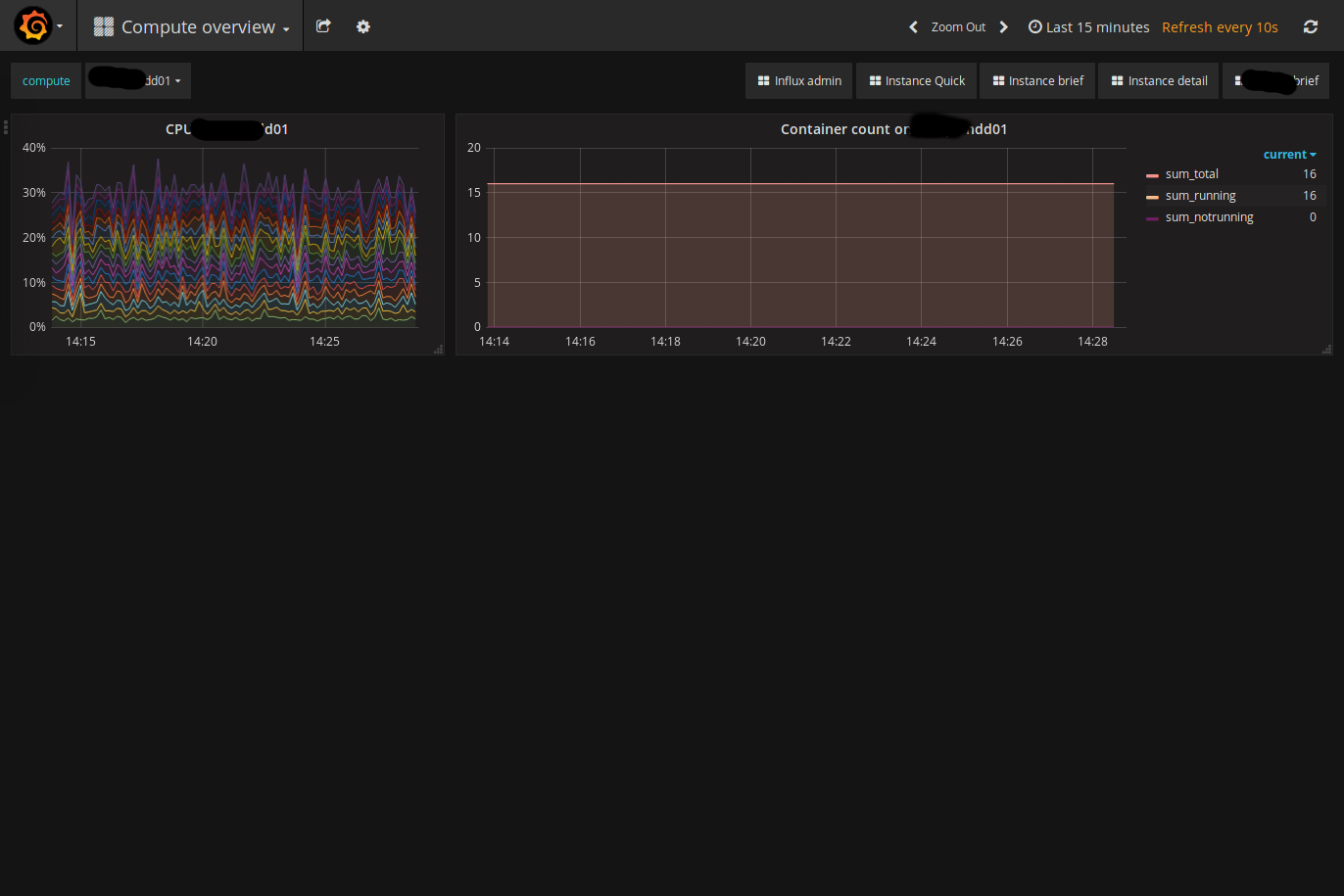
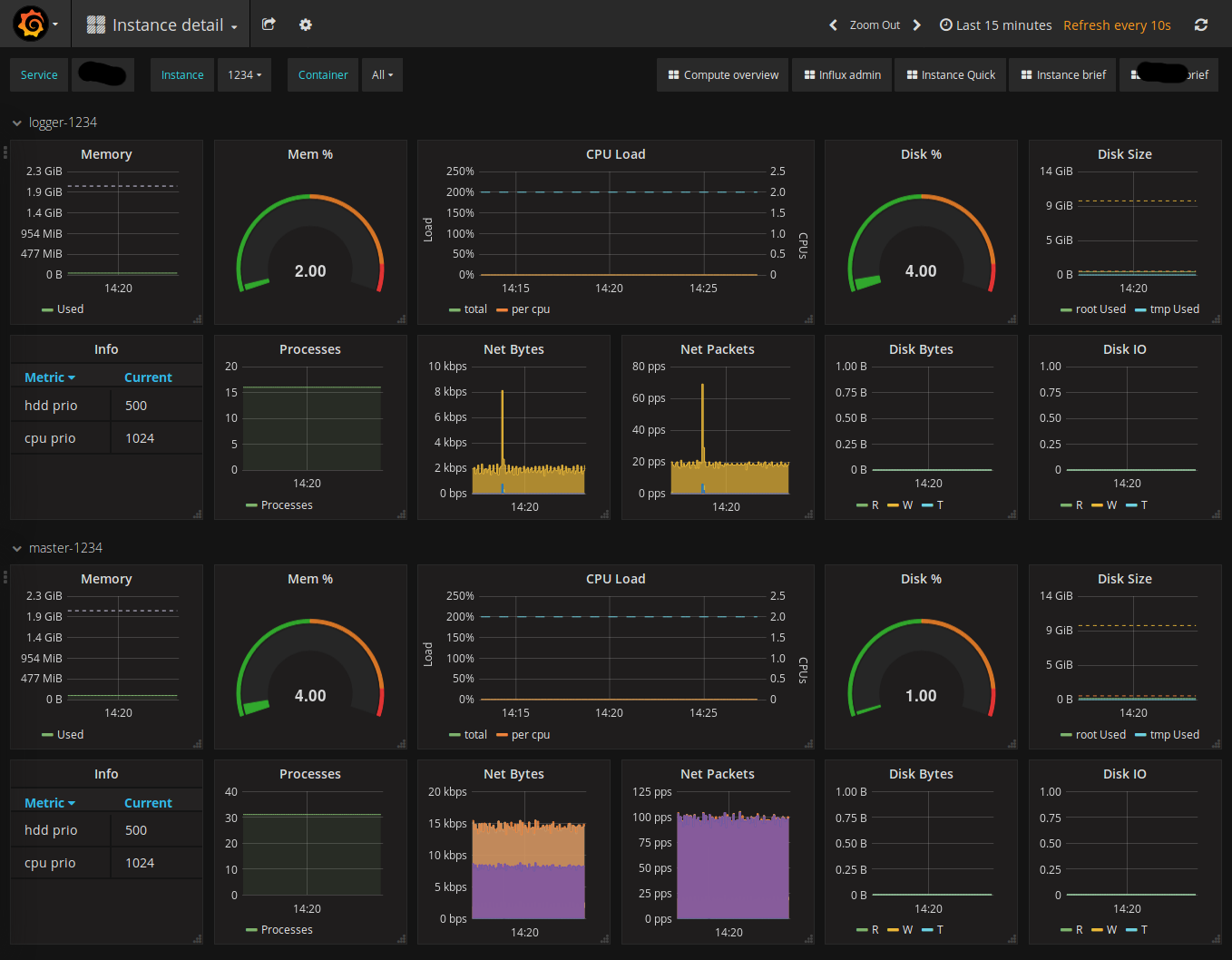

 )
)