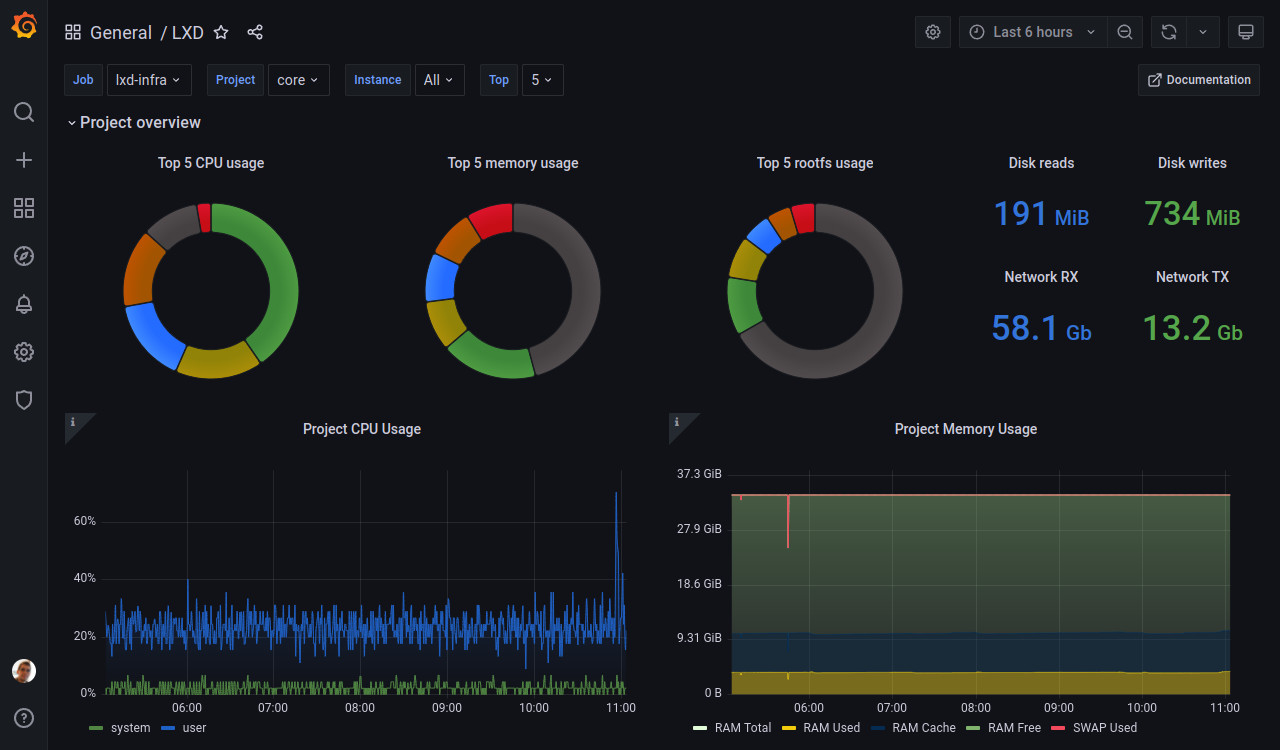
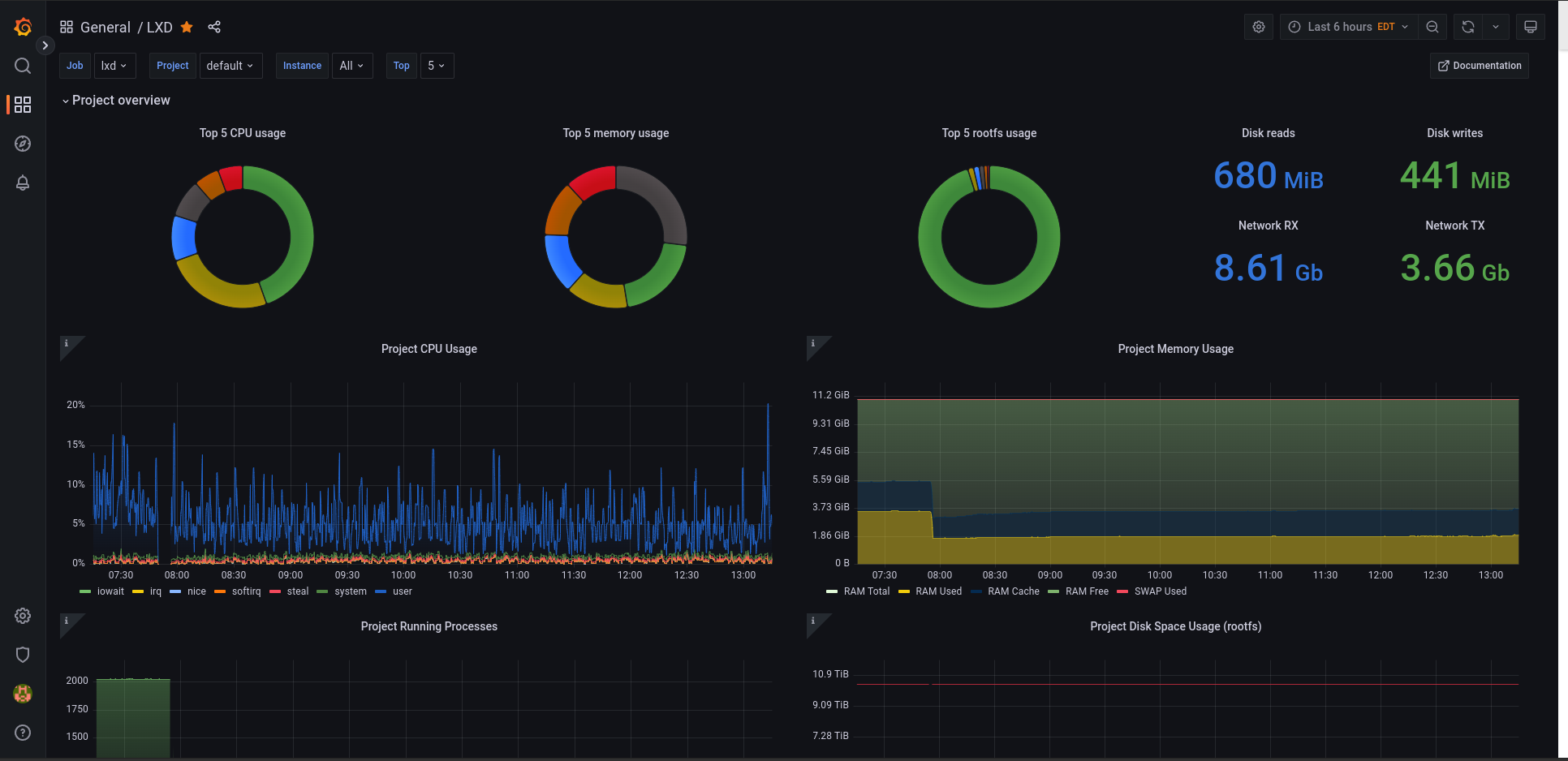
LXD 4.19 introduce support for a metrics interface which exposes an endpoint that’s compatible with the OpenMetrics format.
Combined with a tool like Prometheus, a standalone or clustered LXD deployment can be scrapped at a fixed interval and those metrics be stored in a time series database.
This enables all kind of interesting queries to find performance issues, potential misbehaving workloads, abuses or even gather usage metrics for billing purposes.
Details on how to setup the LXD side of it can be found here:
We’ve then been hard at work on a Grafana dashboard as a showcase of what can be done with those metrics and a good starting point for anyone looking at integrating our metrics with their dashboards.
To set it up, you can import the dashboard id 15726 into your Grafana and pick your prometheus server configured per the instructions above as the data source.
Note that:
You need Grafana 8.4 or higher (required by our disk/network graphs)
You need prometheus 2.22 or higher (required for proper handling of some intervals)
Let us know how well that works for your setup and if there’s anything that we should consider adding. We’ve tried to focus on what a LXD cluster operator may need to identify problems in a multi-project environment.
When using the separate metric listener core.metrics_address, can we have an option that makes the metrics public so that the playing with certs is not necessary ?
That’d probably be fine to add though indeed restricted to the metrics-only listener.
Feel free to file a feature request at https://github.com/lxc/lxd/issues
snap refresh lxd --channel=5.0 will move you to the 5.0 LTS track from the 4.0 LTS track.
Instances will keep running during the update, only thing that goes offline is the LXD API itself, so not different from a normal minor bugfix update.
Any chance anyone has an example of a prometheus.yml file using multiple hosts in the scrape_config with tls?
The example here: Instance metrics - LXD documentation only show how a single target can be configured. I can’t figure out how it should look like for more than one…
Here’s my small scrape_configs which includes a few standalone LXD servers (c2d, ocelot, xeon, mars, jupiter) and a cluster (hdc) comprised of 3 nodes (abydos, langara and orilla). The hdc cluster as a whole was probably bootstrapped by abydos because they all have it’s cert. On that cluster, I only have access to a single project named sdeziel.